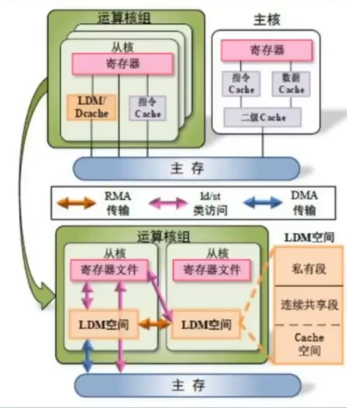
主核存储系统:
- 一级指令Cache 32KB
- 一级数据Cache 32KB
- 二级Cache 512KB
从核存储系统:
- 一个指令Cache 32KB
- 每个从核有256KB数据存储空间(LDM)
 img
img
从核私有变量:_thread int a[100];
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| 混合静态编译及链接
swgcc -mhost master.c
swgcc -mslave slave.c
swgcc -mhybrid master.o slave.o -o a.out
混合动态编译及链接
swgcc -mhost -FPIC -c master.c
swgcc -mslave -FPIC -c slave.c
swgcc -mdynamic -shared master.o slave.o -o libmix.so
mpi编译
mpicc -mhost mater.c
mpicc -mslave slave.c
mpicc -mhybrid master.o slave.o -o a.out
-mhost 编译主核代码
-mslave 编译从核代码
-mhybrid/-mdynamic 静态/动态链接
-msimd SIMD扩展编程接口 (建议从核加)
-mieee 允许使用精确结果的任何操作 (主核必加)
-faddress_align=n 所有数组、向量、结构体按照首地址 nB对齐 主核(n=32)从核(n=64)
-mftz 发生下溢时,将真零写入目标寄存器 (建议主核加)
-O[0/1/2/3/s] 优化级别
-lm -lm_slave 提供高性能快速数据库链接 (主核-lm,从核-lm_slave)
-g 方便gdb调试
-mfma 对乘加操作合成一条操作,建议增加
|
说明:
-faddress_align=64内存对齐,加了这个编译选项后,
就无需在定义数组时候加__attribute__ ((aligned(64)))
例如:
1
| int arr[16] __attribute__ ((aligned (64)))= {1,2,3,4,5,6,7,8,10,11,12,13,14,15};
|
SIMD数据向量化支持512位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| CRTS_init();
athread_spawn();
athread_join();
athread_halt();
CRTS_tid --从核号(0-63)
CRTS_rid --从核所在行(0-7)
CRTS_cid --从核所在列(0-7)
CRTS_cgn --从核所在核组号(0-5)
CRTS_spc_tid --从核簇方式的逻辑从核号(0-63)
CRTS_spcn --从核簇号(0-16)
CRTS_dma_iget(void *dst, void *src, int len, crts_rply_t *rply);
CRTS_dma_iget_stride(void *dst, void *src, int len, int bsize, int stride, crts_rply_t *rply);
CRTS_dma_wait_value(crts_rply_t *rply, int value);
CRTS_dma_iput(void *dst, void *src, int len, crts_rply_t *rply);
CRTS_dma_input_stride(void *dst, void *src, int len, int bsize, int stride, crts_rply_t *rply);
|
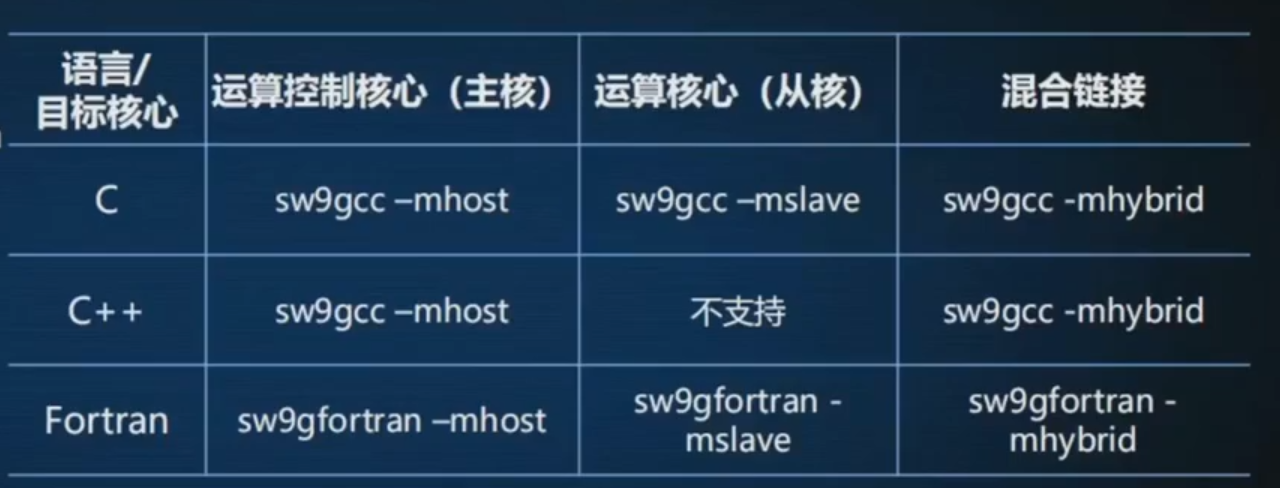
编译
 img
img
1
2
3
4
5
| sw9gcc -mhost -c main.c
sw9gcc -mslave -c slave.c
sw9gcc -mhybrid main.o slave.o -o a.out
|
作业提交
1
| bsub -I -q q_sw_expr -b -n 1 -cgsp 64 -host_stack 1024 -share_size 6000 test.exe
|
- -I
程序输出打印到终端,终端关闭则程序停止运行,若想去掉该项,则加上"-o
out.log",输出内容会重定向到out.log文件,终端关闭程序也不会停止
- -q 程序提交到q_sw_expr计算节点队列运行
- -n 程序运行使用的核组数,最好是4的倍数(一个节点有4个核组)
- -b 从核函数栈变量放在从核局部存储上(必选)
- -cgsp 从核的个数,设置64
- -host_stack 指定主核栈的空间大小,默认8M,一般设置128M以上
- -share_size 指定核组的共享空间大小,一般share_size+host_stack
≤7500
1
2
3
4
5
6
7
8
| bjobs
bkill 作业号
qload -w
|
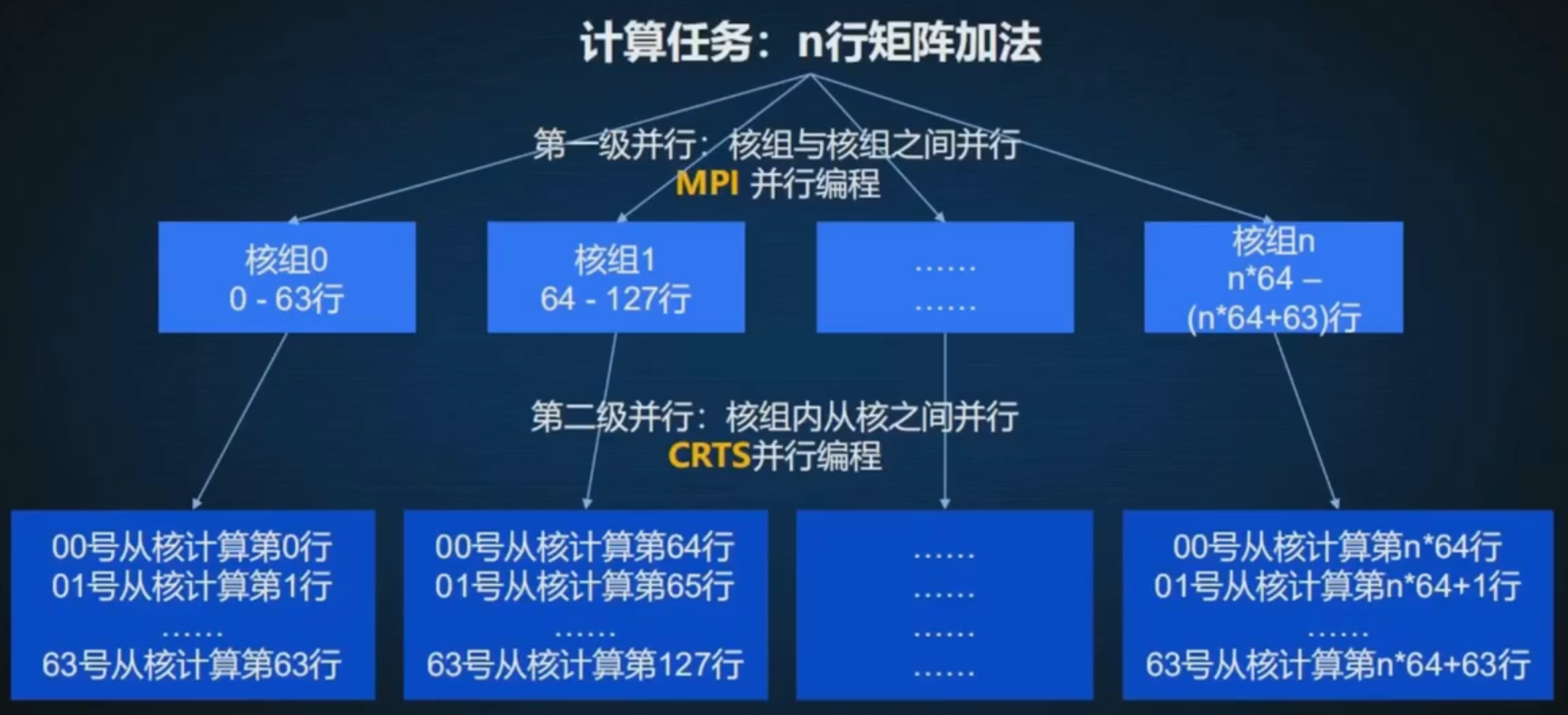
两级并行
 img
img
性能分析
swprof
使用方法:在bsub命令中增加-swrunarg '-p'
 img
img