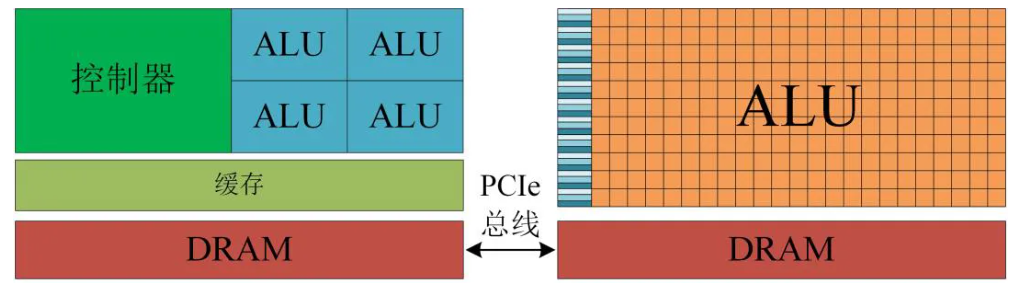
CPU+GPU组成异构计算,GPU可以看做是CPU的协作处理器,一般称为设备
主机(CPU)和设备(GPU)之间的内存访问是通过PCIe总线连接的
| CPU | GPU | 层次 |
|---|---|---|
| 算术逻辑和控制单元 | 流处理器(SM) | 硬件 |
| 算术单元 | 批量处理器(SP) | 硬件 |
| 进程 | Block | 软件 |
| 线程 | thread | 软件 |
| 调度单位 | Warp | 软件 |
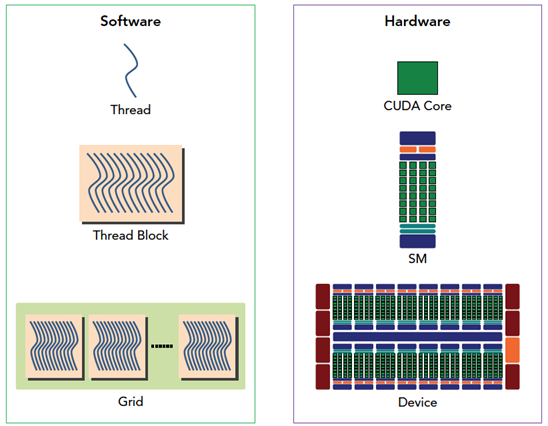
一个线程在一个CUDA Core执行(SP)
一个线程块被分配到一个SM上面执行
一个Grid在GPU设备执行
查看显卡利用率
1 | nvidia-smi |
1、核函数(Kernel_function)
核函数在GPU上进行并行执行
注意:
- 限定词_global_修饰
- 返回值必须是void
- 核函数只能访问设备(GPU)内存
- 核函数不能使用变长参数、静态变量、函数指针
- 核函数具有异步性
1 | _global_ void kernel_function(argument *arg) |
2、线程模型
2.1基本概念
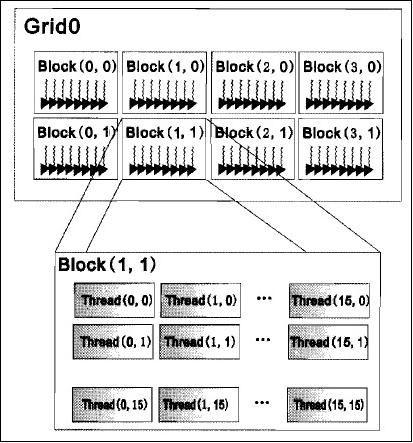
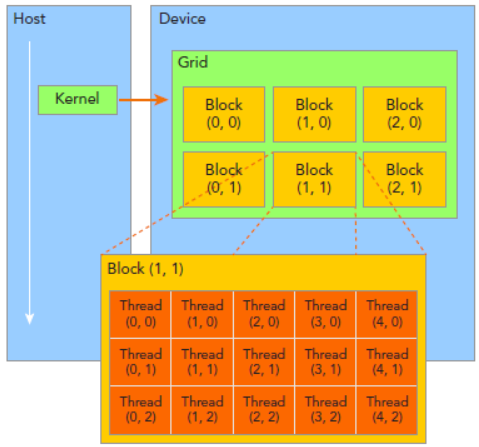
线程分块是逻辑上的划分,物理上线程不分块
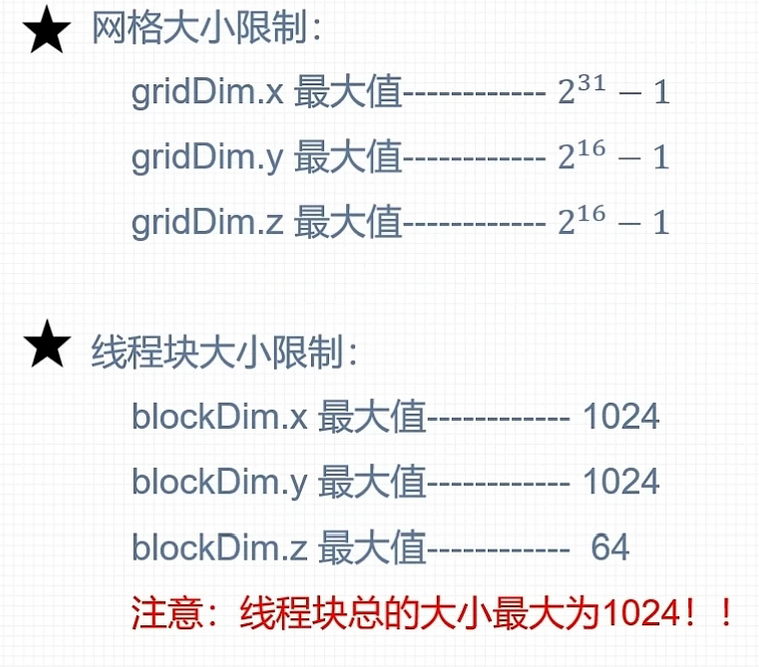
配置线程:<<<grid_size , block_size>>>
grid_size:网格包含的线程块个数 block_size:线程块包含的线程个数
2.2一维身份标识
每个线程的唯一标识由<<<grid_size, block_size>>>确定。
在核函数中可以使用
gridDim.x:该变量的值等于执行配置中变量grid_size的值(线程格的维度)
blockDim.x:该变量的值等于执行配置中变量block_size的值(线程块的维度)
blockIdx.x:线程在网格(grid)中的线程块(block)的索引,范围0~gridDim.x-1(线程块的索引)
threadIdx.x:线程在线程块中的线程索引,范围0~blockDim.x-1(线程索引)

CUDA可以组织三维的网格和线程块
blockIdx和threadIdx都是结构体,具有x,y,z三个成员

一维:

多维:
1 | dim3 grid_size(Gx,Gy,Gz); |
3、函数修饰符
global:表明被修饰的函数在设备上执行,但在主机上调用
device:表明被修饰的函数在设备上执行,但只能在其他__device__函数或者__global__函数中调用。
4、常用的GPU函数
cudaMalloc (void **devPtr, size_t size)
功能:与C语言中的malloc函数一样,只是此函数在GPU的内存你分配内存。
cudaMemcpy (void dst, const void src, size_t count, cudaMemcpyKind kind)
功能:与c语言中的memcpy函数一样,只是此函数可以在主机内存和GPU内存之间互相拷贝数据。
函数参数:cudaMemcpyKind kind表示数据拷贝方向,如果kind赋值cudaMemcpyDeviceToHost表示数据从设备内存拷贝到主机内存,cudaMemcpyHostToDevice表示主机到设备。
相应的有个异步方式执行的函数cudaMemcpyAsync()
cudaFree ( void* devPtr )
功能:与c语言中的free()函数一样,只是此函数释放的是cudaMalloc()分配的内存。
__syncthreads()
功能:同步函数,确保线程块中的每个线程都执行完__syscthreads()前面的语句后,才会执行下一条语句。
cudaDeviceSynchronize();
功能:同步,CPU等待GPU处理完成,注意此函数是CPU函数!
1 |
|
5、GPU内存分类
5.1全局内存
通俗意义上的设备内存
5.2共享内存
位置:设备内存。
形式:关键字__share__添加到变量声明中,如:**__share__ float a[10]**
访问速度和L1相同
5.3常量内存
位置:设备内存
形式:关键字__constant__添加到变量声明中,如:__constant__ float a[10]
目的:为了提升性能。常量内存采取了不同于全局内存的处理方式,在某些情况下用常量内存替换全局内存能有效的减少内存带宽。
6、计时
1 |
|
7、获取GPU名字
1 | cudaDeviceProp deviceProp; |
8、线程束(Wrap)
线程束是SM中基本的执行单元
(SM是Streaming Multiprocessor的缩写,它是指图形处理器(GPU)中的一个核心处理单元)
一个线程束由32个连续的线程组成。是执行程序时的调度单位,同在一个warp的线程执行同一个指令。
为什么要引入Wrap?
虽然GPU的Grid和Block的大小很大,可以拥有上万级别的线程,但因为硬件的限制,不是所有线程都是可以平行运行的。在运行thread的时候, thread会被捆绑到一起形成一个wrap。32个thread一个wrap。 同一个wrap里的指令是一样的,也就是他们运行的东西是一摸一样的,数据也相同。一个wrap里的线程只允许在同一个block里面运行。为了让程序的运行更加有效,需要让同一个wrap里的线程运行同样的代码。
看一个代码:
1 | __global__ void code_with_divergence() |
上面这个这个代码会让效率减少一半。因为当运行A的时候,会让满足条件的那一半thread运行,而另一半的thread会被休眠。
注意:不是写了if语句就一定会让运行效率降低。只要能保证用一个wrap里的线程运行同样的指令就可以提升效率,比如如下代码:
1 | __global__ void code_without_divergence() |
代码是以一个wrap为整体去运行的,所以不会影响运行效率。
9、如何设置grid和block
前言:
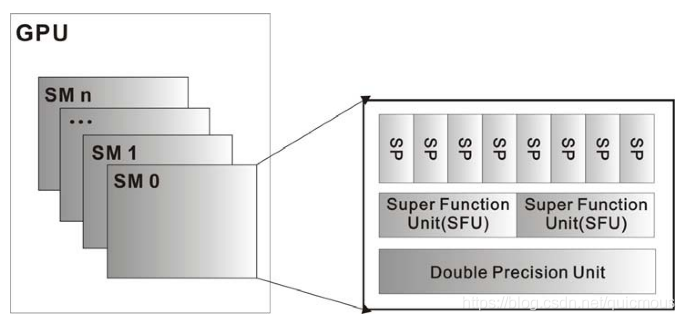
GPU 由多个 SM 处理器构成,一个 SM 处理器包含 8 个 SP 核。一个 SM 处理器可同时处理 32 个线程(Wrap束),实际上是同一套指令在每个 SP 核上重复 4 次, 这样提交一次任务,8 个SP 核同时就能处理 32 个线程。
设置grid和block维度
如果某个GPU拥有 16 个 SM 处理器,共 128 个 SP 核(16*8)。
- 如果想让每个 SM 处理器都工作,则 Grid 的 Block 的数量最好是 16 的整数倍。这样在整个计算过程中,每个 SM 处理器负载都是一样的。
- 每个 SM 处理器同时可以处理 32 个线程,因此,Block 中的线程数量最好是 32 的倍数,使得 8 个 SP 核负载均衡。
由上可知,应该按照16N32M = 512S的划分模式,也就是说,理想的数据量应该是 512 的整数倍。同时要注意,一个线程块线程数量不能多于1024!
1.一维grid,一维block
1 | int nx = 1 << 14; |
核函数
1 | __global__ void kernel_function() |
2.二维grid,一维block
1 | int nx = 1 << 14; |
核函数
1 | __global__ void kernel_function() |
3.二维grid,二维block
1 | int nx = 1 << 14; |
核函数
1 | __global__ void kernel_function() |
文档
https://www.zhihu.com/tardis/bd/art/566538074
https://zhuanlan.zhihu.com/p/573271688