一、Hello world
1 |
|
1 | mpicxx hello.cpp -o hello |
1 | mpirun -np 10 ./hello |
代码结构:
- 头文件
- 初始化MPI环境:MPI_Init()
- 分布式代码
- 终止MPI环境:MPI_Finalize()
- 结束
二、基本API
2.1 初始化环境 MPI_Init
1 | int MPI_Init(int* argc,char* argv[]); |
2.2 是否初始化:MPI_Initialized
1 | int MPI_Initialized(int *flag) |
唯一可在MPI_Init前使用的函数,用来检测MPI系统是否已经初始化,已经调用MPI_Init,返回flag=true,否则返回flag=false。
2.3 终止环境:MPI_Finalized
1 | int MPI_Finalize(void) |
在一个进程执行完其全部MPI函数调用后,将调用函数MPI_Finalize,从而让系统释放分配给MPI的资源(例如内存等)
2.4 获取进程数:MPI_Comm_size
1 | int MPI_Comm_size(MPI_Comm comm, int* size) |
通过调用函数来确定一个通信域中的进程总数。
如果comm是MPI_COMM_WORLD,那就是当前程序能用的所有进程数
2.5 获取进程ID:MPI_Comm_rank
1 | int MPI_Comm_rank(MPI_Comm comm, int* rank) |
在一个有p个进程的通信域中,每一个进程有一个唯一的序号(ID号),取值为0~p-1。
当MPI初始化后,每一个活动进程变成了一个叫MPI_COMM_WORLD的通信域中的成员。
2.6 获取程序运行的主机名
1 | int MPI_Get_processor_name(char* name, int* resultlen) |
- name:返回名称
- resultlen:返回名称所占用的字节
应提供参数name不少于MPI_MAX_PROCESSOR_NAME个字节的存储空间。
2.7 终止一个comm的所有进程:MPI_Abort
1 | int MPI_Abort(MPI_Comm comm, int errorcode) |
异常终止MPI程序,在出现了致命错误而希望异常终止MPI程序时执行,MPI系统会设法终止comm通信器中的所有进程,输入整形参数errocode,将被作为进程的退出码返回给系统。
2.8 同步栅栏函数 MPI_Barrier
1 | void MPI_Barrier(MPI_Comm communicator) |
可以用二叉树、双回环等方式实现,依靠的是Send、Recv阻塞机制
三、通信API
- MPI提供了消息的缓存机制
- 消息可以以阻塞或非阻塞的方式发送
- 顺序性:MPI保证接收者收到消息的顺序和发送者的发送顺序一致
- 公平性:MPI不保证调度公平性,程序员自己去防止进程饥饿
3.1 MPI消息数据类型
| MPI 数据类型 | C 语言数据类型 | MPI 数据类型 | C 语言数据类型 |
|---|---|---|---|
| MPI_CHAR | signed char | MPI_UNSIGNED | unsigned int |
| MPI_SHORT | signed short int | MPI_UNSIGNED_LONG | unsigned long int |
| MPI_INT | signed int | MPI_FLOAT | float |
| MPI_LONG | signed long int | MPI_DOUBLE | double |
| MPI_LONG_LONG | signed long long int | MPI_LONG_DOUBLE | long double |
| MPI_UNSIGNED_CHAR | unsigned char | MPI_BYTE | |
| MPI_UNSIGNED_SHORT | unsigned short int | MPI_PACKED |
3.2 点对点通信
status参数用于指出接收的消息的源和标记(status.MPI_SOURCE、status.MPI_TAG)如果不关心这些参数,可以用MPI_STATUS_IGNORE
阻塞发送/接收:
1
2
3
4
5
6
7
8
9int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
// buf: 发送缓冲区起始地址
// count: 发送消息的数据单元个数
// datatype: 发送消息的数据类型
// dest: 目标进程号
// tag: 发送消息的标签
// comm: 通信域
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
//status可以用MPI_STATUS_IGNORE忽略使用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
void main(int argc, char* argv[])
{
int numprocs, myid, source;
MPI_Status status;
char message[100];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
if (myid != 0) { //非0号进程发送消息
strcpy(message, "Hello World!");
MPI_Send(message, strlen(message) + 1, MPI_CHAR, 0, 99,
MPI_COMM_WORLD);
}
else { // myid == 0,即0号进程接收消息
for (source = 1; source < numprocs; source++) {
MPI_Recv(message, 100, MPI_CHAR, source, 99,
MPI_COMM_WORLD, &status);
printf("接收到第%d号进程发送的消息:%s\n", source, message);
}
}
MPI_Finalize();
}非阻塞发送/接收:
1
2
3
4
5
6
7
8
9
10int MPI_Isend(const void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request* request)
// buf: 发送缓冲区起始地址
// count: 发送消息的数据单元个数
// datatype: 发送消息的数据类型
// dest: 目标进程号
// tag: 发送消息的标签
// comm: 通信域
// request: 非阻塞发送请求对象
int MPI_Irecv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request)
//通过request可以知道Isend或Irecv的状态(是否完成)MPI_Wait用于等待某一个通信的完成,MPI_Waitall等待一组通信的完成1
2int MPI_Wait(MPI_Request *request, MPI_Status *status)
//status可用`MPI_STATUS_IGNORE`代替1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (size != 2) {
std::cerr << "This program requires exactly 2 MPI processes." << std::endl;
MPI_Abort(MPI_COMM_WORLD, 1);
}
const int N = 10;
std::vector<int> data(N);
MPI_Request request;
MPI_Status status;
if (rank == 0) {
for (int i = 0; i < N; ++i) {
data[i] = i;
}
MPI_Isend(data.data(), N, MPI_INT, 1, 0, MPI_COMM_WORLD, &request);
MPI_Wait(&request, &status);
} else if (rank == 1) {
MPI_Irecv(data.data(), N, MPI_INT, 0, 0, MPI_COMM_WORLD, &request);
MPI_Wait(&request, &status);
std::cout << "Process 1: Data received." << std::endl;
std::cout << "Process 1: Received data = ";
for (int i = 0; i < N; ++i) {
std::cout << data[i] << " ";
}
std::cout << std::endl;
}
MPI_Finalize();
return 0;
}
3.3 集合通信
3.3.1 广播 Bcast
从指定的一个根进程中把相同的数据广播发送给组中的所有其他进程
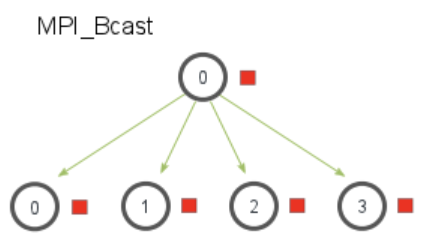
1 | MPI_Bcast( |
for循环调用MPI_Send和MPI_Recv也能实现广播的效果,但是时间复杂度有很大的区别,for循环实现时间复杂度为O(n),Bcast实现时间复杂度为O(logn)
Bcast的实现示意图:
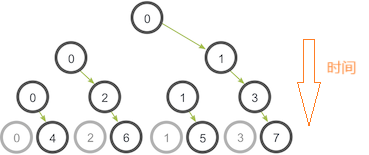
- T0时刻:0号进程将数据传递给1号进程
- T1时刻:0号进程和1号进程都有了数据,0号进程将数据发送给2号进程,1号进程发送给3号进程
- T2时刻:0->4,1->5,2->6,3->7
3.3.2 分发 Scatter
把指定的根进程中的数据分散发送给组中的所有进程(包括自己)
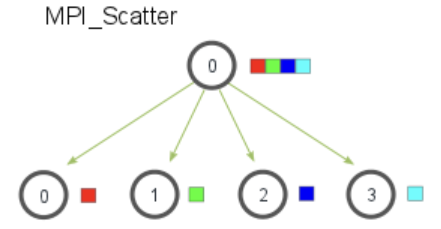
1 | MPI_Scatter( |
3.3.3 收集 Gather
在组中指定一个进程收集组中进程发来的消息,这个函数操作与MPI_Scatter函数操作相反 所有进程调用该函数,把指定位置的数据发送给根进程的指定位置
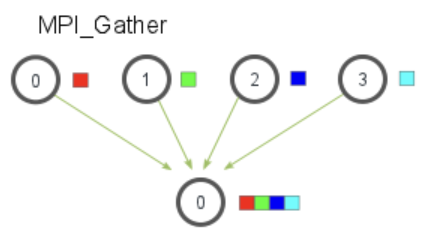
1 | MPI_Gather( |
3.3.4 全收集 Allgather
将所有的数据聚合到每个进程中。
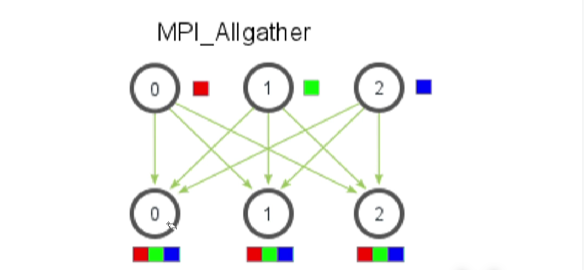
1 | MPI_Allgather( |
与gather的区别就是没有root参数
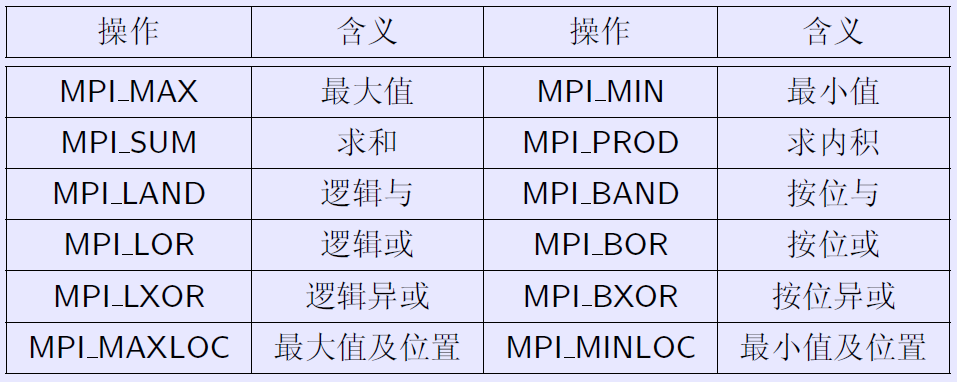
3.3.5 规约 Reduce
将每个进程中的数据按给定的操作op进行运算,并将其结果返回到序列号为root的进程。
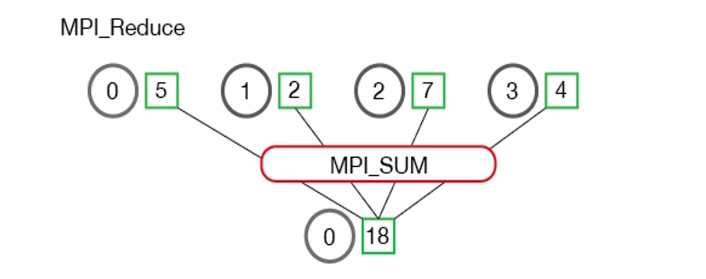
可以处理多个值
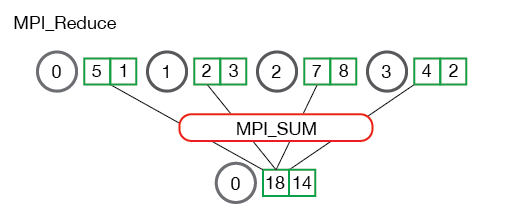
1 | MPI_Reduce( |
3.3.6 全规约 Allreduce
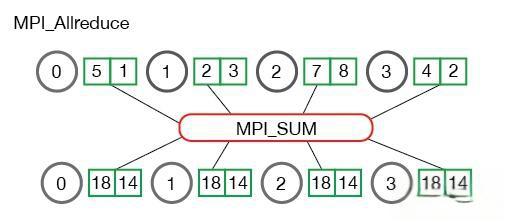
1 | MPI_Allreduce( |
3.4 通信域和进程组
进程组就是一组并行运行的MPI进程的集合,同一进程可以属于不同的进程组
一个进程组可以包含任意数量的进程,而一个通信域由一个进程组构成,但一个进程组可以用于创建多个不同的通信域。
在之前的MPI学习中一直使用的通信域MPI_COMM_WORLD所对应的进程组就是全体进程的集合
1 |
|