编译时需要加上-fopenmp标志:
1 | gcc -fopenmp -o my_program my_program.c |
| 函数 | 概念 |
|---|---|
int omp_get_num_procs() |
返回本线程的多处理机的处理器个数 |
int omp_get_num_threads() |
返回当前并行区域的线程个数 |
int omp_get_thread_num() |
返回当前线程号 |
int omp_set_num_threads() |
设置并行代码执行时线程个数 |
double omp_get_wtime() |
返回以秒为单位的当前时间 |
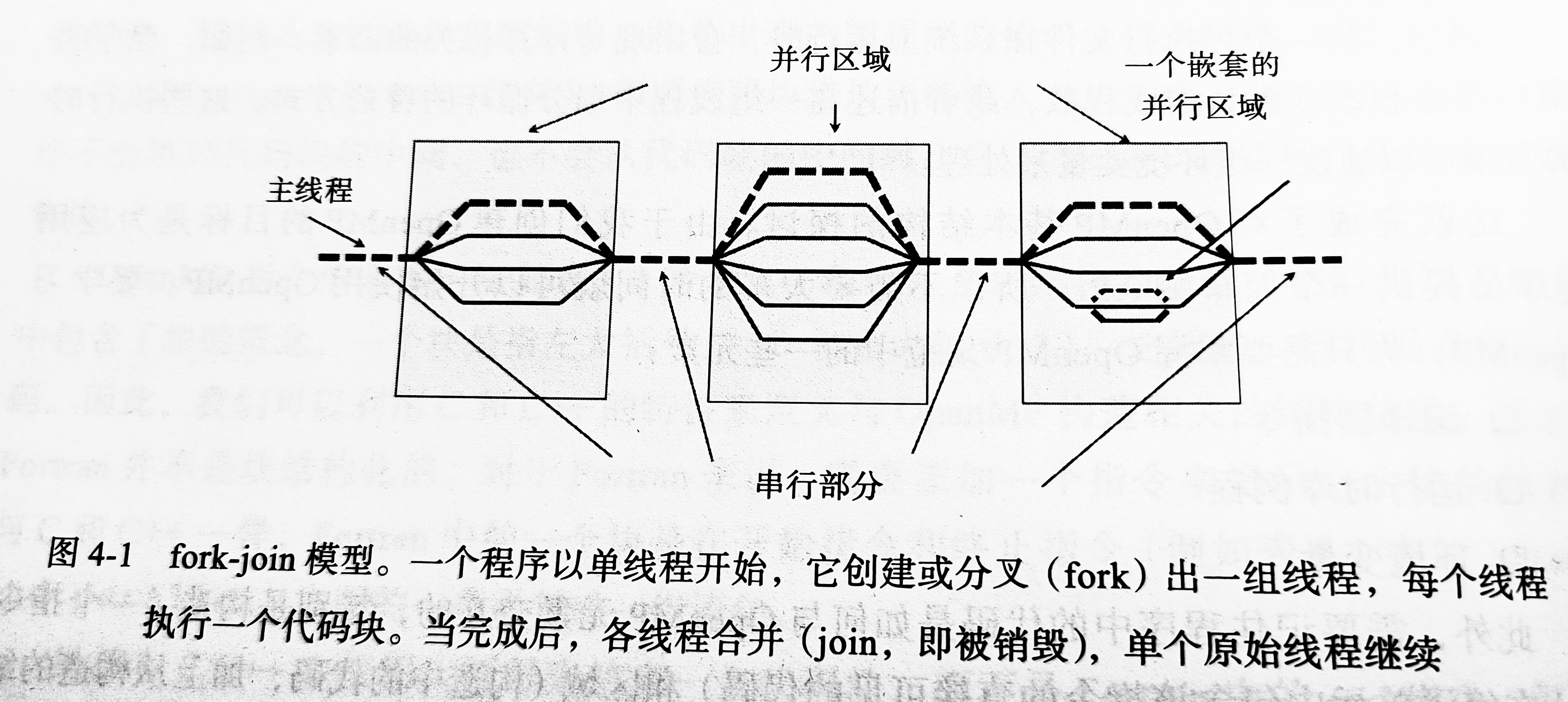
一、openMP语句模式
1 | #pragma omp 指令 子句 子句 子句........ |
二、parallel 制导命令
表示接下来由花括号括起来的区域将创建多个线程并行执行
可以用num_threads来控制使用的线程数目。
1 | #pragma omp parallel num_threads(5) |
函数实现线程数目控制:omp_set_num_threads(5)
获取线程ID:int tid = omp_get_thread_num();
三、for 循环语句
每一个要循环的语句将被分配给不同的线程去执行。
1 | #pragma omp for |
tips:循环体要按照for(int i=0;i<n;i++)的形式,注意int!要在for初始化
1 |
|
parallel 和 for 可以写成一个整体,即:
1 |
|
四、schedule调度指令
schedule子句:schedule(type,size)
- type:①static ②dynamic ③guided ④runtime
- size:整数型,表示循环迭代次数划分单位
1、static参数:静态调度
- 不用size参数时,分配给每个程序的都是n/t次连续迭代(n为迭代次数,t为并行的线程数目)
- 使用size参数,表示每次分配给线程size个连续迭代。
1 |
|
2、dynamic参数:动态调度
先到先得的方式进行任务分配
- 不使用size参数时,空闲线程取一个任务
- 使用size参数时候,空闲线程取size个任务
3、guided参数:
guided开始时每个线程会分配到较大的迭代块,之后分配到的迭代块会逐渐递减。
迭代块的大小会按指数级下降到指定的chunksize大小,如果没有指定chunksize参数,那么迭代块大小最小会降到1。
代码示例:
1 |
|
五、sections制导指令
用sections把不同的区域交给不同的线程去执行
代码示例:
1 |
|
六、变量管理
在没有private指令的时候,默认变量都是各线程之间共享的
private
用#pragma omp private(n)声明可声明一个或多个变量为线程私有副本。
1 | int n = 1 , m = 100; |
firstprivate
private指令只是声明变量私有,但不能继承在主线程中的值,这时就需要用firstprivate了
例如:
1 | int n = 1; |
lastprivate
将经过线程处理的数据重新赋值给主线程的变量 注意: 最终主线程变量的值由最后执行完成的那个线程决定。
1 | int n = 1; |
defualt
default可以设置并行区域的变量使用方式
default(shared)为共享 default(none)为私有
七、single制导语句
single制导指令所包含的代码段只有一个线程执行,别的线程跳过。
如果没有nowait子句,那么其他线程将会在single制导指令结束的隐式同步点等待。
有nowait子句其他线程将跳过等待往下执行。
1 | #pragma omp single |
八、互斥
critical、Lock、atomic三者的耗时比约为
7 : 3.5 :1
1、critical
Critical区域是一段代码,在同一时刻只能被一个线程执行。当一个线程进入Critical区域时,其他线程就需要等待该线程执行完毕后才能进入这个区域。使用#pragma omp critical指令来创建Critical区域。
1 | int x=0; |
2、atomic
atomic是原子操作,速度最快,但是只能保护一条C语言赋值语句形成的临界区 语句必须按照:x {op} = {expression}的形式 如:x++、x--、--x、++x
op可以是以下任意的二元操作符:+、-、*、/、&、^、|、<<、>>
注意:expression不能引用x,如:x+=x,这是不允许的
1 | int x = 0; |
3、锁
一种显式的同步机制,可以用于保护共享资源,也可以用于控制线程执行的顺序
在OpenMP中,我们可以使用omp_lock_t类型的变量
omp_init_lock(&omp_lock)初始化锁
omp_set_lock(omp_lock)上锁
omp_unset_lock(&omp_lock)解锁
omp_test_lock(&omp_lock)测试锁,上锁状态返回0,否则为1,当前线程不会发生阻塞
omp_destroy_lock(&omp_lock)撤销锁
1 | omp_lock_t lock; |
九、规约子句
使用规约子句将并行区域末尾计算出的结果与原始值合并
使用:reduction(op:list)
| 运算符 | 初始值 |
|---|---|
| + | 0 |
| * | 1 |
| - | 0 |
| min | 规约列表类型中最大可表示数 |
| max | 规约列表类型中最小可表示数 |
1 |
|
十、遇到的问题
10.1 伪共享
OpenMP在多核处理器间进行同步时常常需要共享一些变量,如用多线程同时对一个数组初始化时,多个线程对同一个数组进行修改,即使线程间从算法上并不需要共享变量,但是在实际执行时,若不同线程所需要赋值的地址处于同一个缓存行中,就会引起缓存冲突,严重降低程序性能,这就是伪共享。
作者:先进编译实验室 https://www.bilibili.com/read/cv28352985/ 出处:bilibili
通常可以通过以下方式减少伪共享
- 尽可能使用专用数据;
- 利用编译器的优化功能来消除内存负载和存储。
在某些情况下,更改数据的分配方式可以减少伪共享。在其他情况下,通过更改迭代到线程的映射,为每个线程的每个块分配更多的工作(通过更改 chunksize 值),也可以减少伪共享。
十一、扩展发现
11.1 flush子句
flush可以强制刷新每个线程的缓存,在使用共享变量时如果出现伪共享可以尝试用这个方法
1 |
|
11.2 task子句


为了避免一个任务被重复地定义, 需要single 子句

11.2.1 depend子句
depend
子句允许你显式地指定任务之间的数据依赖关系,帮助编译器和运行时系统确定哪些任务可以并行执行,哪些任务必须顺序执行。依赖关系的类型包括:
in:表示任务只读取数据。
out:表示任务只写入数据。
inout:表示任务既读取又写入数据。
1 |
|