本篇参考:
学东西要沉住气,”慢就是稳,稳就是快“
一、前序
并行性
程序是一系列指令和数据的集合,因此并行就可以分为指令并行和数据并行
我们通常更关注数据并行,openmp、pthread很多操作都是为了数据并行
- 指令并行:利用流水线、超标量、乱序执行等技术,使得多条指令可以同时或部分重叠地执行
- 数据并行:在多个处理单元之间实现的,通过将数据划分成若干块,并分别映射到不同的处理单元上
CUDA非常适合数据并行
异构计算
异构:不同的计算机架构就是异构
x86 CPU+GPU的异构是最常见的
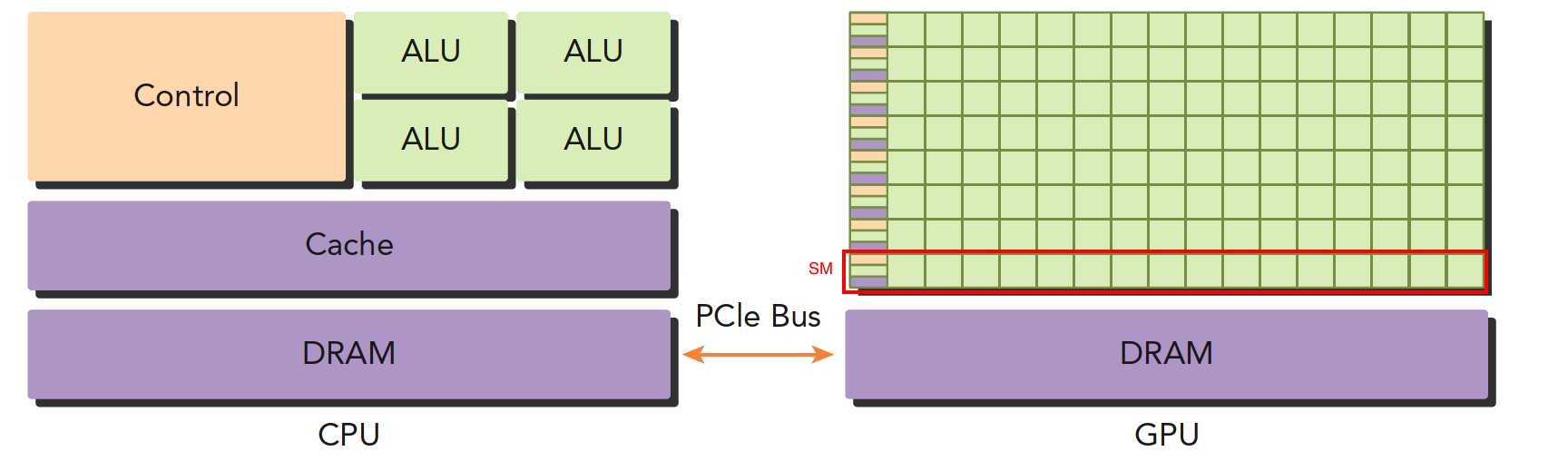
- ALU:逻辑计算单元,也就是核心,就是我们常说的四核
- Control:控制单元
- Cache:缓存
- DRAM:内存
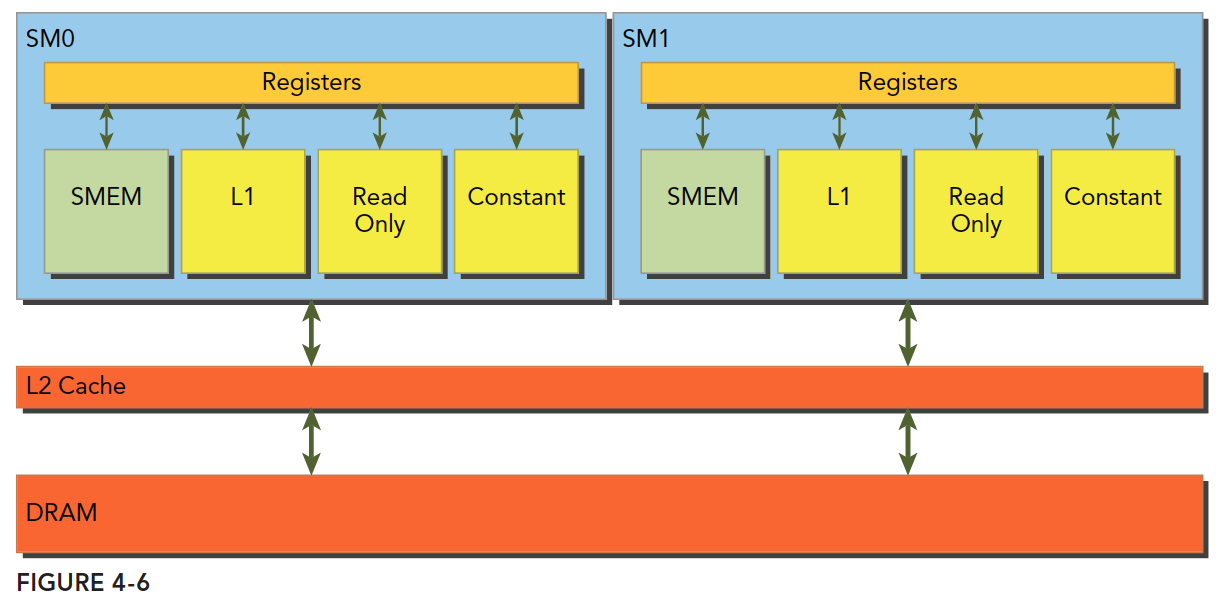
GPU中一个SM(红色框部分)可以看作是一个完整的多核CPU,只是ALU数量变多了,
因此GPU对数据量大的计算任务适应性更好,对于逻辑复杂的程序一个SM是不如一个CPU
注意:一个GPU是由若干多个SM(streaming multiprocessor),可以把SM看成GPU的大核,寄存器register和共享内存shared memory是SM的稀缺资源
CPU和GPU之间通过PCIe总线进行连接(有的采用的是NVLink)
GPU架构
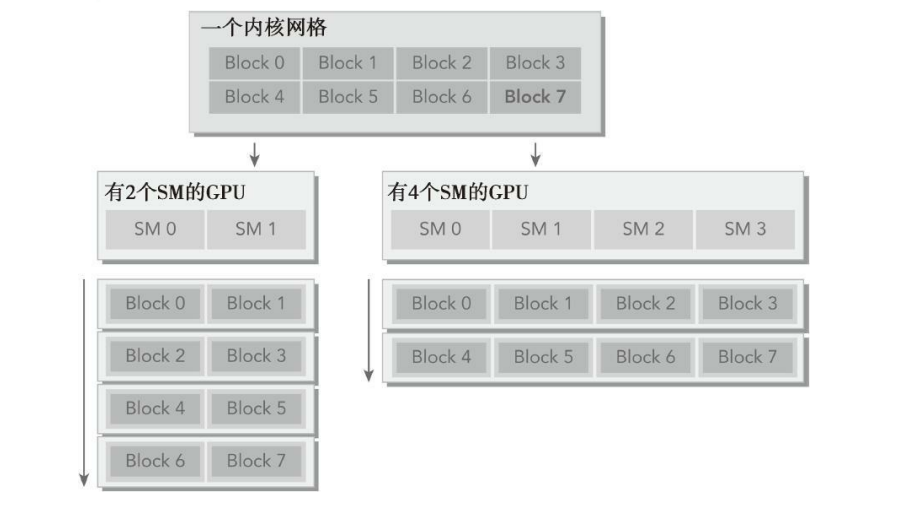
GPU是围绕SM(流式多处理器)的扩展阵列搭建的,通过复制结构实现硬件并行。
GPU中每个SM都能支持数百个线程并发执行,
当一个核函数被启动的时候,多个block会被同时分配给可用的SM上执行。
Fermi 费米架构
第一个完整的GPU架构,最大可支持16个SM,每个SM有32个Core,共512个Core
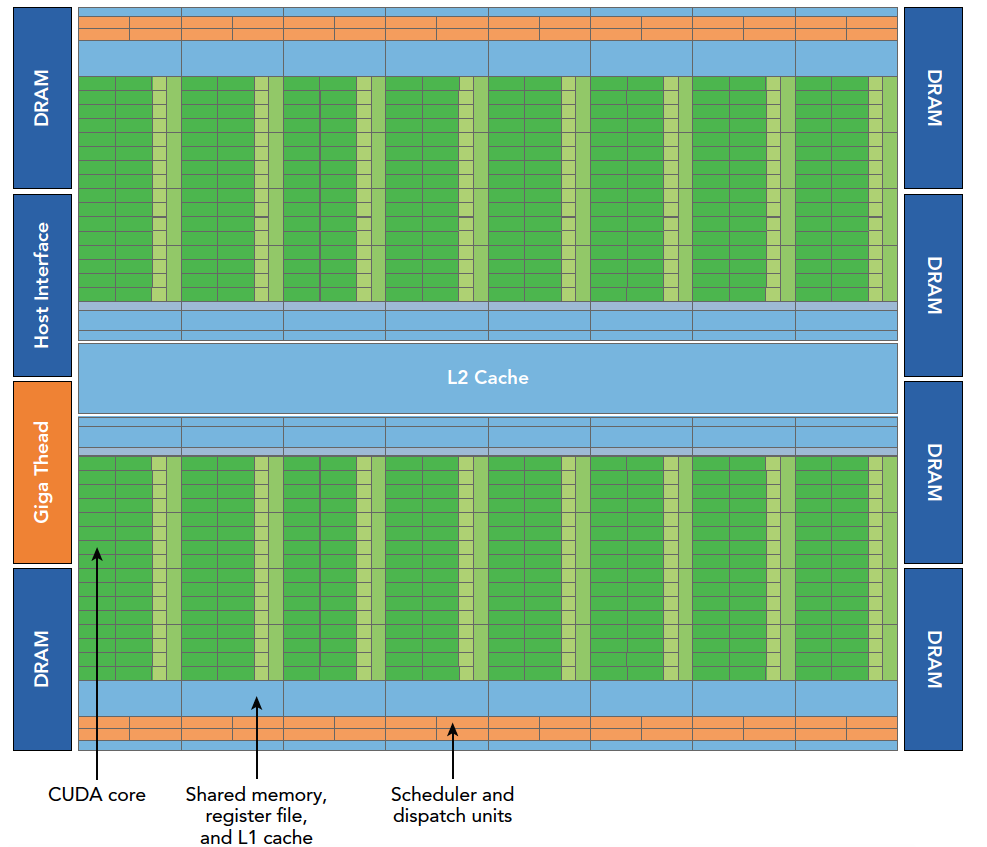
其中一个SM的结构如下:
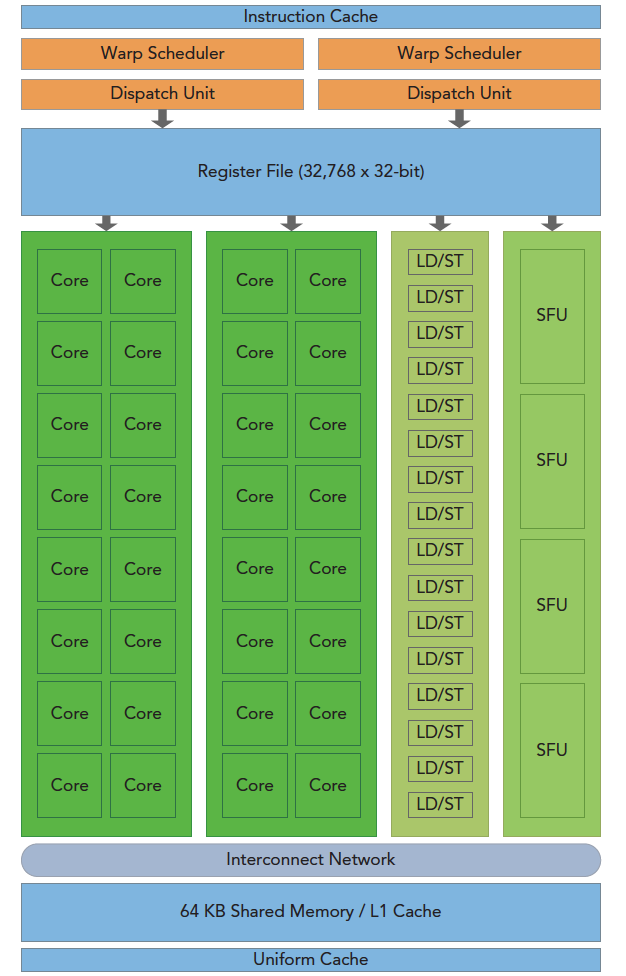
https://cloud.tencent.com/developer/article/1443485
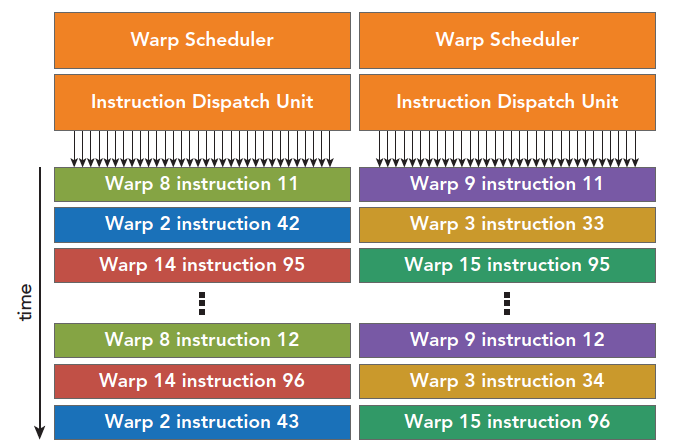
其使用的是双Wrap调度机制,Wrap的线程数和运算单元数(Core)没必要关系,利用时钟周期,具体流程如下:
- 第一个时钟周期:两个调度器调度不同两个Warp的16个线程(Half Warp)到各自的16个Core上运算
- 第二个时钟周期:两个调度器调度剩余的Half Warp到Core上
二、补充知识
即是没有GPU,CPU也可以完成计算,只是速度会慢很多,所以把GPU看作是CPU的加速设备(加速卡)
NVIDIA目前的计算平台(不是架构):
- Tegra:嵌入式芯片,功耗低,gpu和cpu芯片在同一块硅片上
- Geforce:图像用户
- Quadro:专业绘图,支持高速OpenGL渲染
- Tesla:用于大规模并行计算
CUDA平台不是单单指软件或者硬件,而是建立在Nvidia GPU上的一整套平台,并扩展出多语言支持
三、基础
3.1 GPU信息获取
3.1.1 程序内信息获取
具体参见:https://blog.csdn.net/weixin_45791458/article/details/136379581
API在更新,最好是查阅最新的官方文档!
3.1.2 nvidia-smi
指令可以直接获取当前设备GPU信息,通过添加不同的参数获取不同的信息
1 | root@dsw-425468-7489bfcb8-jfhdt:/mnt/workspace# nvidia-smi |
最具体的信息可以用如下命令查询
1 | nvidia-smi -q [-i No] |
更多用法可以nvidia-smi -h 或者 手册查询
3.2 第一个程序Hello world
1 |
|
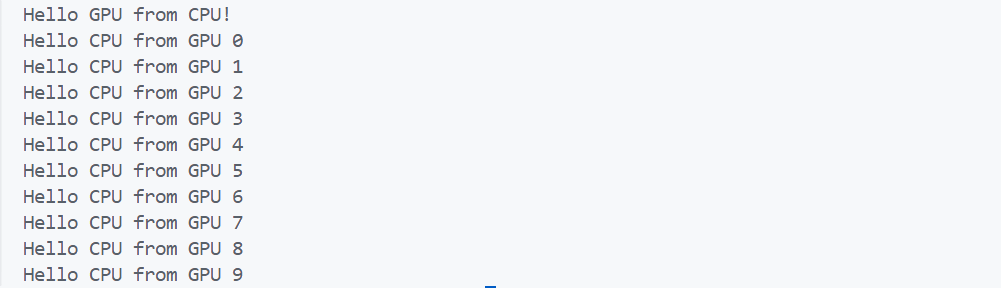
__global__关键字告诉编译器此函数是在GPU上执行的核函数print_kernel<<<1,10>>>()运行核函数cudaDeviceReset()这个函数包含有隐式同步,CPU必须等GPU执行完成才接着执行,cudaDeviceSynchronize()则是显示同步
整个代码结构
- 分配GPU的内存
- 拷贝数据到GPU
- 调用核函数执行计算
- 将计算完的数据拷贝回主机
- 释放内存
3.3 初识内存
CUDA提供了一套进行内存管理的API,既可以管理设备端的内存也可以管理主机端的
但是主机端通常还是用传统的标准库进行管理。
| 标准C函数 | CUDA API | 说明 |
|---|---|---|
| malloc | cudaMalloc | 分配内存 |
| memcpy | cudaMemcpy | 内存拷贝 |
| memset | cudaMemst | 数据设置 |
| free | cudaFree | 释放内存 |
3.2.1 cudaMemcpy
内存数据拷贝的过程是通过总线完成的
1 | cudaError_t cudaMemcpy(void * dst,const void * src,size_t count,cudaMemcpyKind kind) |
如果函数执行成功,则会返回cudaSuccess 否则返回
cudaErrorMemoryAllocation
1 | char* cudaGetErrorString(cudaError_t error) |
使用此指令即可把错误代码翻译成详细的信息
3.2.2 cudaMalloc
1 | cudaError_t cudaMalloc (void **devPtr, size_t size ); |
第一次遇到我也很好奇,为什么第一个参数是两个星星
1 | float *device_data=NULL; |
目的是为了将 device 上分配的内存地址通过形参传出来。
3.2.3 示例
1 |
|
3.4 初识线程
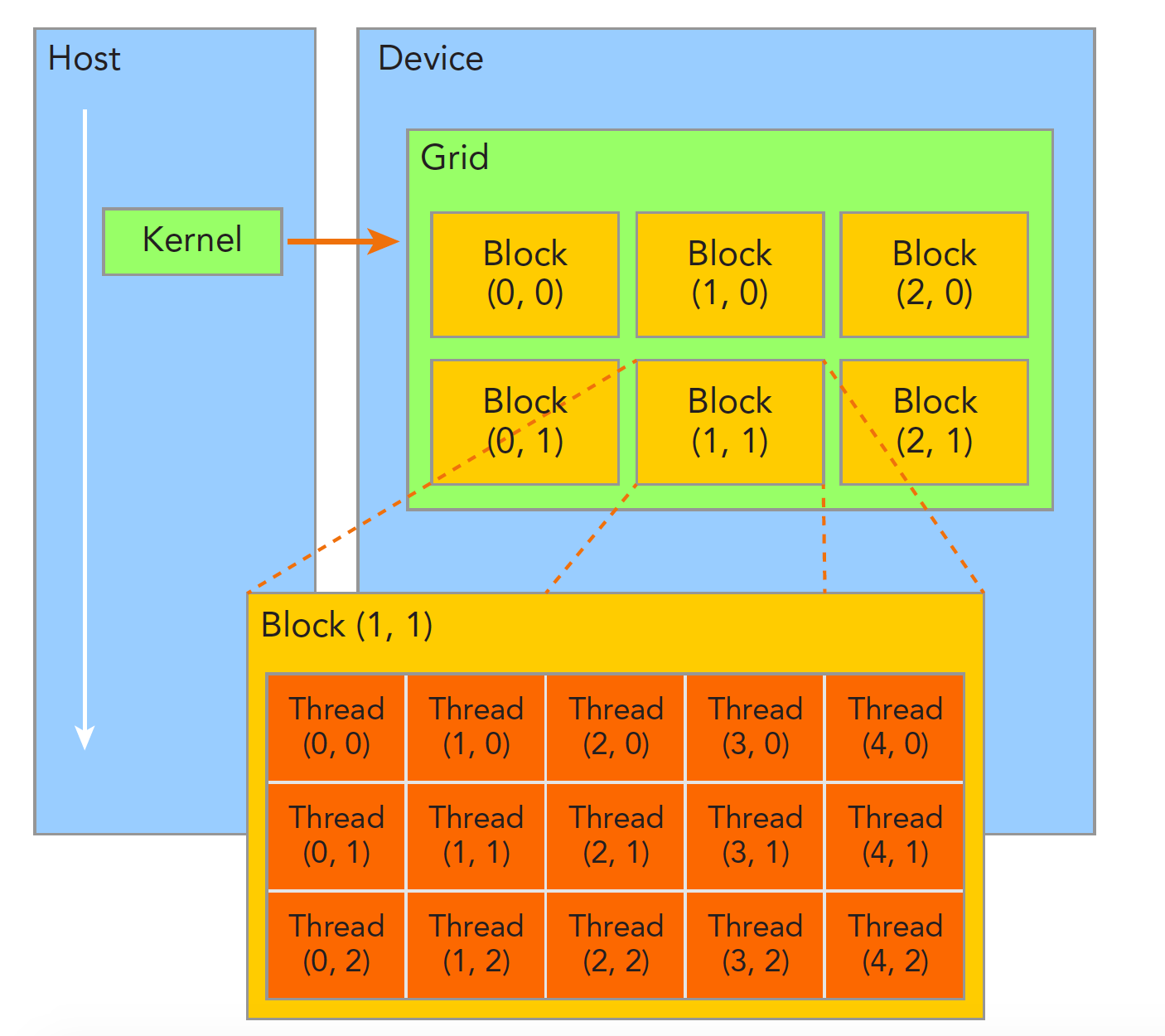
首先要明白,一个kernel对应一个Grid,一个Grid里面有很多块,每个块又可以包含许多线程
线程块内部线程之间可以实现同步和共享内存,不同线程块之间是物理隔离的
gridDim.x、gridDim.y、gridDim.z分别表示Grid各个维度的大小
blockDim.x、blockDim.y、blockDim.z分别表示线程块中各个维度的大小
blockIdx.x、blockIdx.y、blockIdx.z分别表示当前线程块所处的线程格的坐标位置
threadIdx.x、threadIdx.y、threadIdx.z分别表示当前线程所处的线程块的坐标位置
1 | dim3 grid(1,1,1); |
注意:一个块里的线程最大为1024,grid的维度(block的块数)很大,暂时可以不考虑
一维二维示意图如下,三维可自行推

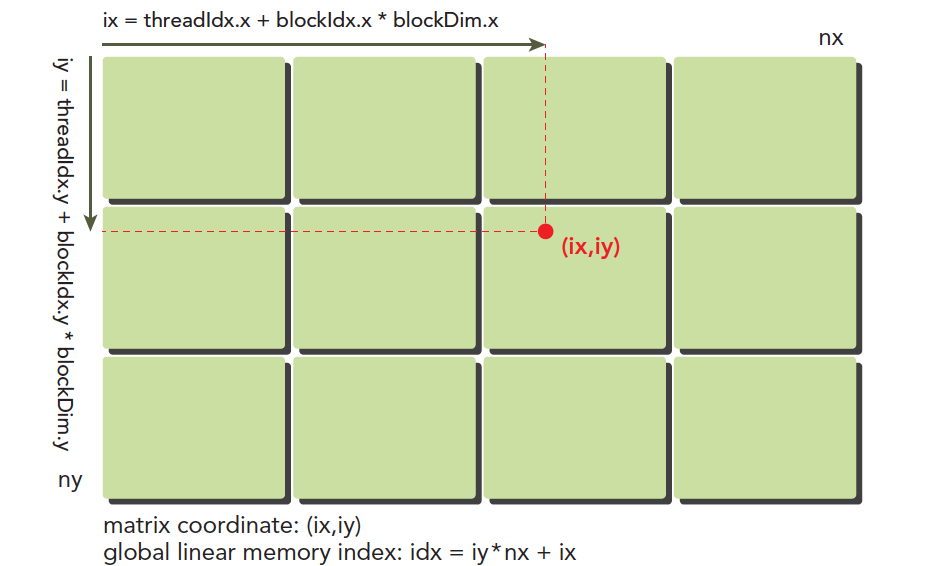
计算出三维的线程编号: \[ tid=threadIdx.x+threadIdx.y×blockDim.x+threadIdx.z×blockDim.x×blockDim.y \]
3.5 核函数 kernel
所有CUDA核函数的启动都是异步的。
__global__:设备端运行,全局(主机端、设备端)都可以调用,返回类型必须是void__device__:设备端运行__host__:忽略,不加关键词默认即这个
有一个特殊情况,就是__device__和__host__同时存在,这样的话CPU和GPU就可以都进行调用,也可以存在返回值
底层实现是编译器编译出了两份功能相同,调用对象不同的代码
1 |
|
Kernel核函数编写有以下限制
- 只能访问设备内存
- 必须有void返回类型
- 不支持可变数量的参数
- 不支持静态变量
- 显示异步行为
3.6 错误处理
1 |
通过这个宏定义就可以进行检查错误
1 | CHECK(cudaMalloc((float**)&a_d,nByte)); |
3.7 计时
3.7.1 CPU计时法
1 |
|
使用这个方法计算得出的时间比GPU计算运行的时间要长
原因:
- 主机调用核函数需要时间
- 主机同步函数需要时间
3.7.2 nvprof
nvprof是分析工具,可以很直观的计算出整个过程时间
1 | nvprof [args] <application> |
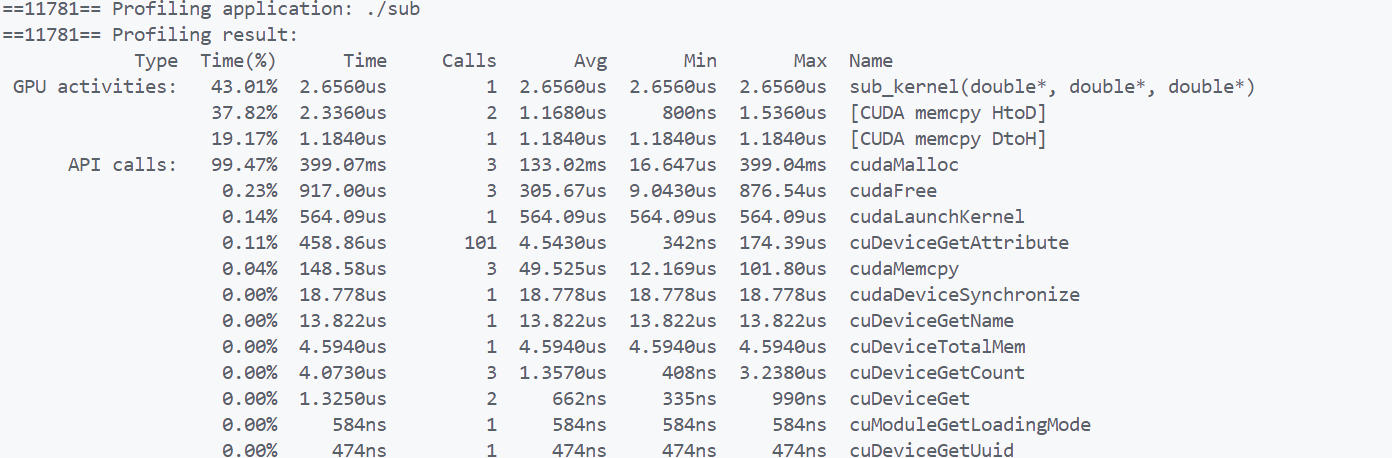
可能会出现如下内容
1 | ======== Warning: nvprof is not supported on devices with compute capability 8.0 and higher. |
其实就是说nvprof工具太老了,让使用NVIDIA Nsight Systems
具体参见:https://zhuanlan.zhihu.com/p/666242337
1 | usage: nsys [--version] [--help] <command> [<args>] [application] [<application args>] |
1 | nsys nvprof ./program [xx] |
3.8 线程束 Warp
warp是调度和运行的基本单元,CUDA 采用单指令多线程SIMT架构管理执行线程,
目前基本所有设备的线程束大小都是32,所以block大小最好是32的倍数
- 被分配到同一个SM上的block是串行执行的。
- 一个block中不同warp是并发执行的。
- 一个warp中的32个线程是并行执行的。
同一个warp内的线程通信,不需要进行同步(barrier)
若一个SM中有8个ALU,但是warp的大小为32,怎么进行并行?
答:分为四个周期执行,每个周期执行8个线程
3.8.1 线程束分化
if...else...、for、while这些可以进行流控制,
1 | if (con) |
假设这段代码是核函数的一部分,那么当一个线程束的32个线程执行这段代码的时候,如果其中16个执行if中的代码段,而另外16个执行else中的代码块,同一个线程束中的线程,执行不同的指令,这叫做线程束的分化。
在同一周期内,同一个线程束的线程执行相同的指令,处理各自私有的数据
因此,第一个指令周期运行if里面的指令,第二个指令周期才会运行else里面的指令
指令周期中,不满足条件的线程就什么也不执行,但是要占用core,所以效率很低。
底层是因为GPU不会为每一个ALU提供独立的分支预测单元。
要解决这个问题根本思路是避免同一个线程束内的线程分化
有一个核函数 (低效):
1 | if (tid % 2){ |
我们可以改为
1 | if ((tid / warpSize) % 2 == 0){ |
分支情况可以通过nvprof进行分析
1 | nvprof --metrics branch_efficiency [app] |
3.8.2 资源
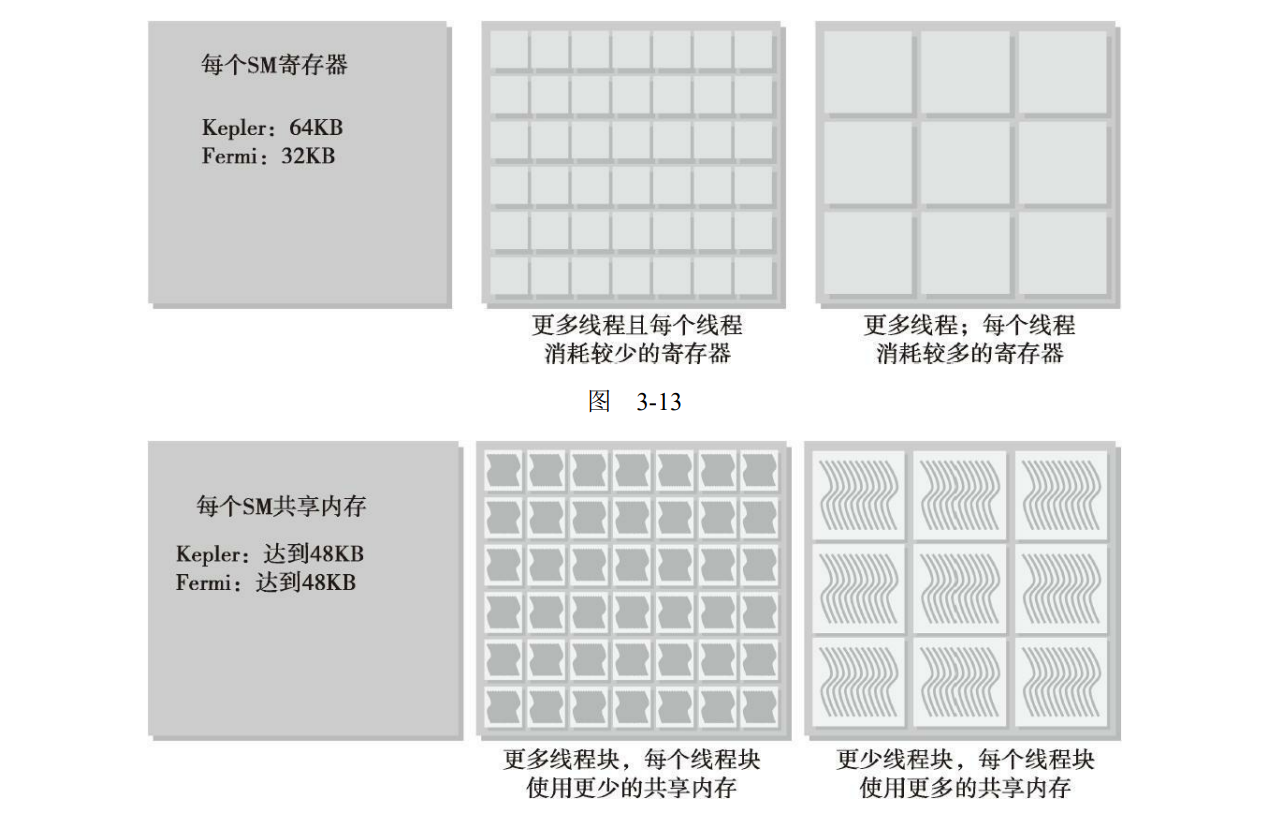
一个SM上被分配多少个线程块和线程束取决于SM中可用的寄存器和共享内存,以及内核需要的寄存器和共享内存大小。
当kernel占用的资源较少,那么更多的线程处于活跃状态,相反则线程越少。
3.8.3 延迟隐藏
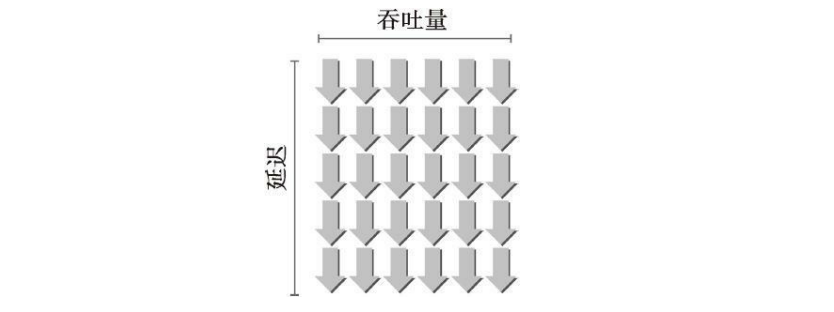
其他类型的编程相比,GPU的延迟隐藏及其重要
指令延迟:计算指令从调用到完成所需时钟周期
➤ 算术类指令:10-20个时钟周期 ➤ 访存类指令:400-800个时钟周期
Q:如何计算满足延迟隐藏所需要的最小线程束数量?
利特尔法则(Little’s Law) \[ 所需线程束数量 = 延迟时间×GPU吞吐量 \] 吞吐量:在一个周期中能并行执行的线程束的数量
假设在内核里一条指令的平均延迟是5个周期。为 了保持在每个周期内执行6个线程束的吞吐量,则至少需要30个未完成的线程束。
3.9 同步
- 系统级:CPU等待GPU完成工作
1 | cudaError_t cudaDeviceSynchronize(); |
- 块级:线程块内所有线程完成工作
1 | __device__ void __syncthreads(); |
不同warp的线程需要进行同步后才能知道处理完的数据
同一个wrap内的线程,不需要同步就可以知道
可以说,块内同步是为了同步warp之间的数据
3.10 并行性分析
由于我使用的是vGPU没办法进行分析,就参考书的内容进行整理。

据图可知,(32,16)的配置效率最高,推断其并行性更好,同一时刻有更多的线程块参与
3.10.1 占用率分析
1 | nvprof --metrics achieved_occupancy ./simple_sum_matrix |

占用率:每周期内活跃线程束的平均数量与一个SM支持的线程束最大数量的比值
可以看到,更高的占用率并不一 定意味着有更高的性能。
3.10.2 内存读取效率
1 | nvprof --metrics gld_throughput ./simple_sum_matrix |

同样的,第四种情况吞吐量最高,但其速度还是慢
所以,更高的加载吞吐量并不一定意味着更高的性能。
3.10.3 全局加载效率
1 | nvprof --metrics gld_efficiency ./simple_sum_matrix |

全局加载效率:实际加载的数据量与理论上需要加载的数据量之间的比值。
举个栗子:
假设你需要10个配料,厨房实际从仓库拿了20个配料,其中只有10个是你需要的。
- 所需的全局加载吞吐量 = 10个配料(你真正需要的量)
- 被请求的全局加载吞吐量 = 20个配料(厨房实际带回的量)
加载效率就为50%
可以看到第一个和第二个的全局加载效率都很高,但是第一个速度也比较慢
3.10.4 提高并行性
由上面几个即可总结,
- 保证一个块的内层维数应该是线程束大小的倍数(block的x,横向)
- 线程块最内层维度的大小对性能起着的关键的作用
- 一个单独的指标不能产生最佳的性能,需要综合考虑寻找平衡点
3.11 避免分支分化
假设要对一个有N个元素的整数数组求和
1 | int sum = 0; |
我们队规约操作有如下几种方法
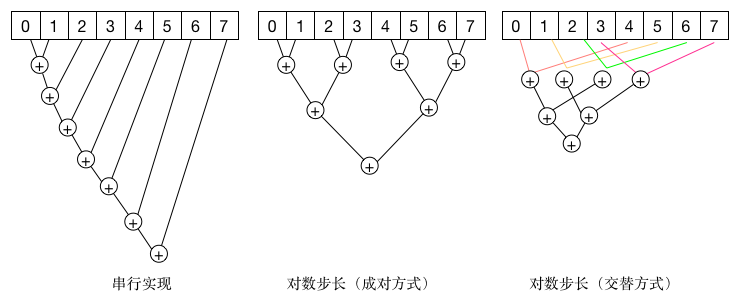
由上图可知,串行的规约计算需要7步,性能较差。
成对的方式是分治思想,只需要\(lgN\)步就可以完成
CPU+GPU完成规约方法如下图所示:
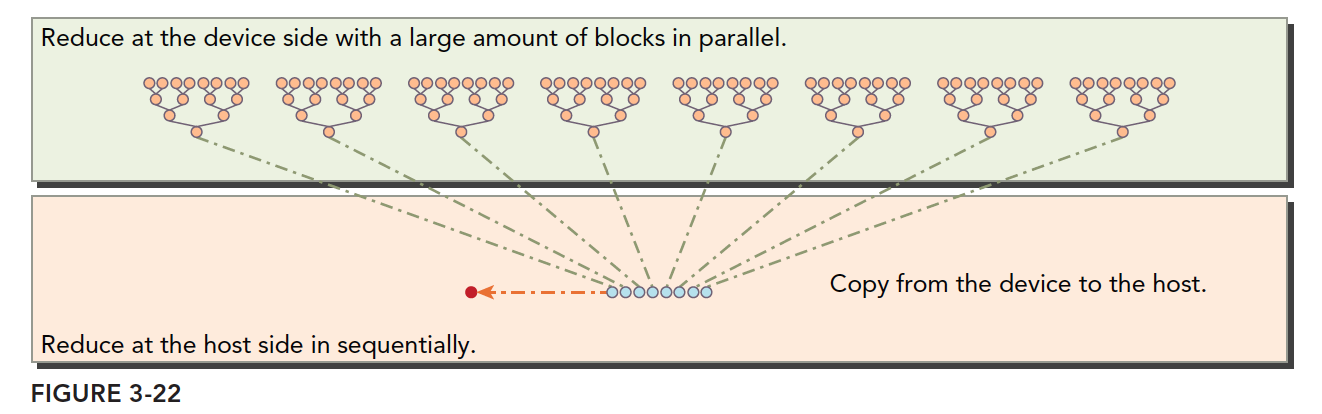
相邻规约实现
1 | __global__ void reduceNeighbored(int * g_idata,int * g_odata,unsigned int n) |
可以看到存在线程分化问题,
1 | if ((tid % (2 * stride)) == 0) |
第一轮 有\(\frac{1}{2}\)的线程没有使用
第二轮 有\(\frac{3}{4}\)的线程没有使用
第三轮 有\(\frac{7}{8}\)的线程没有使用
因为这些线程在一个线程束,所以,只能等待,不能执行别的指令。
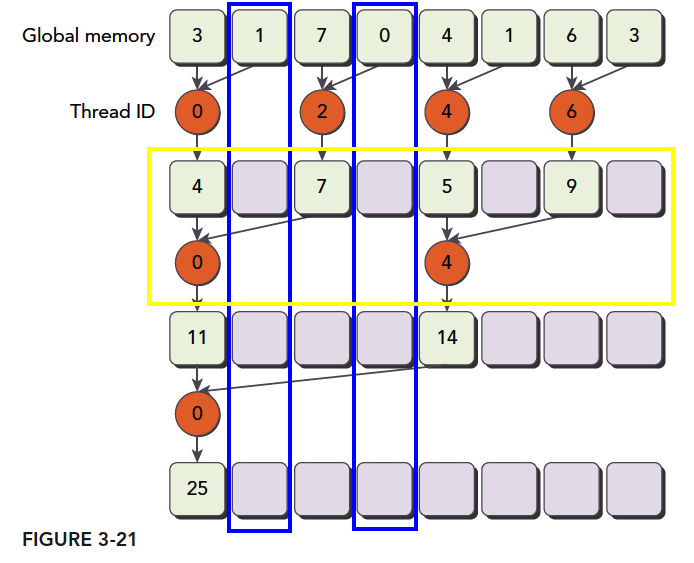
所以,我们可以修改为如下方法
橙色小球为线程序号,
1 | __global__ void reduceNeighboredLess(int * g_idata,int *g_odata,unsigned int n) |
这个方案保证了一个线程块中前半部分线程束warp接近慢的,后半部分线程束基本是不需要执行,硬件会停止他们从而去调用别人
例如:16线程的块,前8个线程束执行第一轮归约,剩下8个什么也不做;第二轮中前4个执行归约,后12个什么也不做
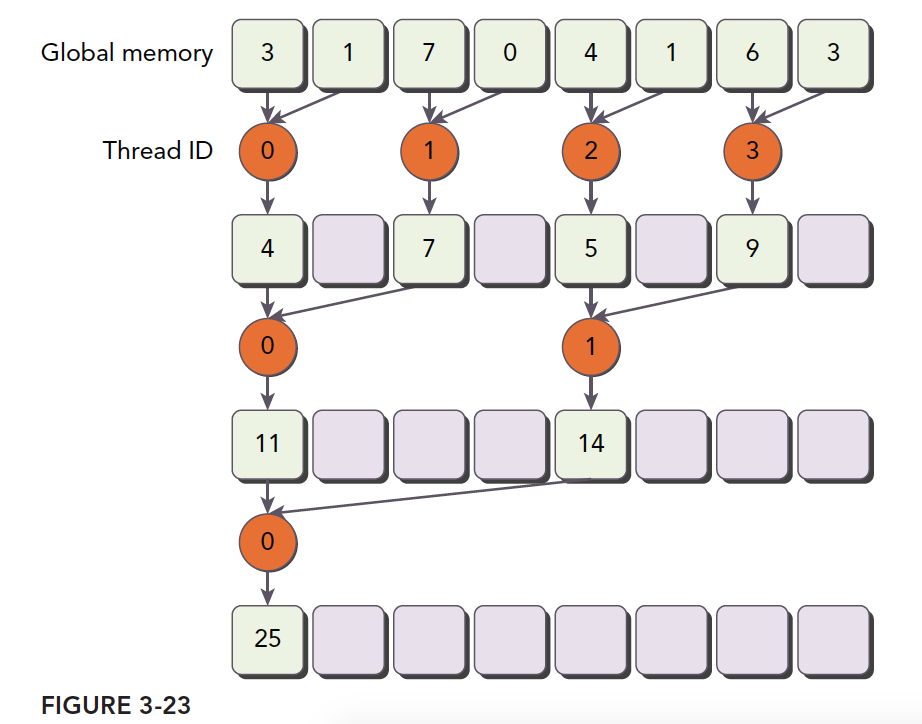
交错配对规约
1 | __global__ void reduceInterleaved(int * g_idata, int *g_odata, unsigned int n) |
3.12 动态并行
CUDA的动态并行允许在GPU端直接创建和同步新的GPU内核。
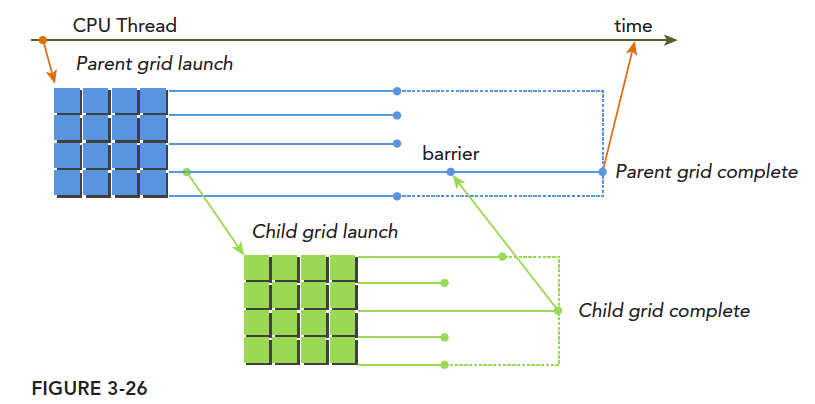
子网格被父线程启动,且必须在对应的父线程结束之前结束。
主机启动一个网格(也就是一个内核)-> 此网格(父网格)在执行的过程中启动新的网格(子网格们)->所有子网格都运行结束后-> 父网格才能结束,否则要等待
图中通过设置栅栏的方法,显式的同步了父网格和子网格,
如果调用的线程没有显示同步子网格,那么运行时保证,父网格和子网格会隐式同步。
父网格中的不同线程会启动的不同子网格,这些子网格拥有相同的父线程块,他们之间是可以同步的
- 父网格和子网格共享相同的全局和常量内存
- 父网格和子网格有不同的局部内存
了解即可,感觉这功能有点鸡肋,
- 不能降低代码复杂度
- 运行效率没有提高
- 内存管理也变复杂了
例子:
1 |
|
编译可能会出现如下报错:
1 | error: kernel launch from __device__ or __global__ functions requires separate compilation mode |
解决方法:https://blog.csdn.net/u014683187/article/details/100741727
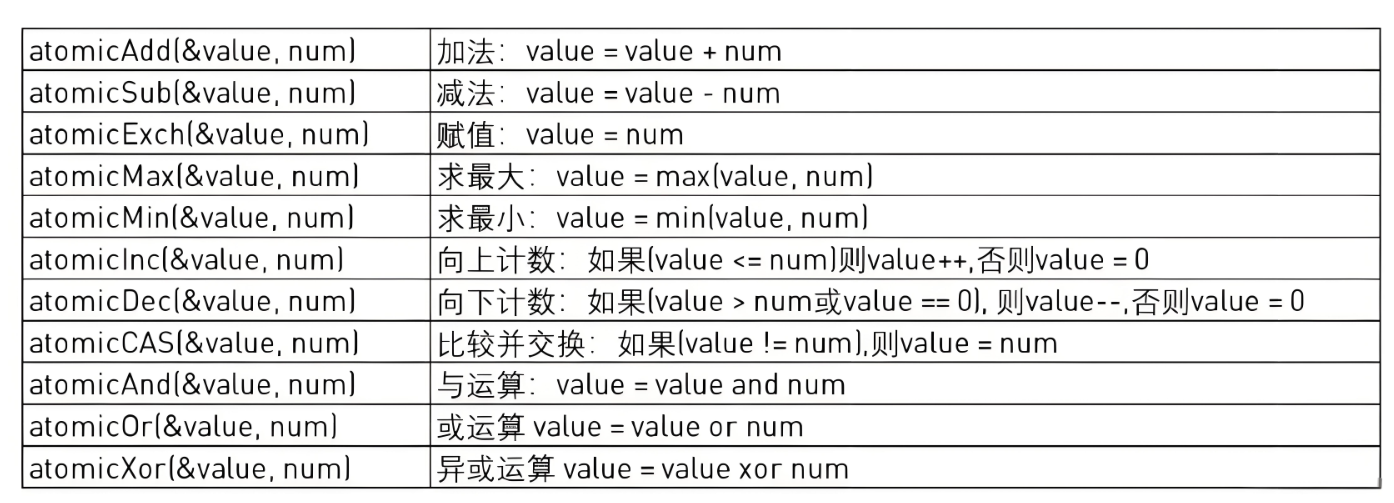
3.13 原子操作
CUDA的原子操作可以理解为对一个Global memory或Shared memory中变 “读取-修改-写入” 这三个操作的一个最小单位的执行过程
在它执量进行行过程中,不允许其他并行线程对该变量进行读取和写入的操作。
四、内存
CPU和GPU的主存都采用的是DRAM(动态随机存取存储器),而低延迟内存(如 CPU一级缓存)使用的则是SRAM(静态随机存取存储器)。
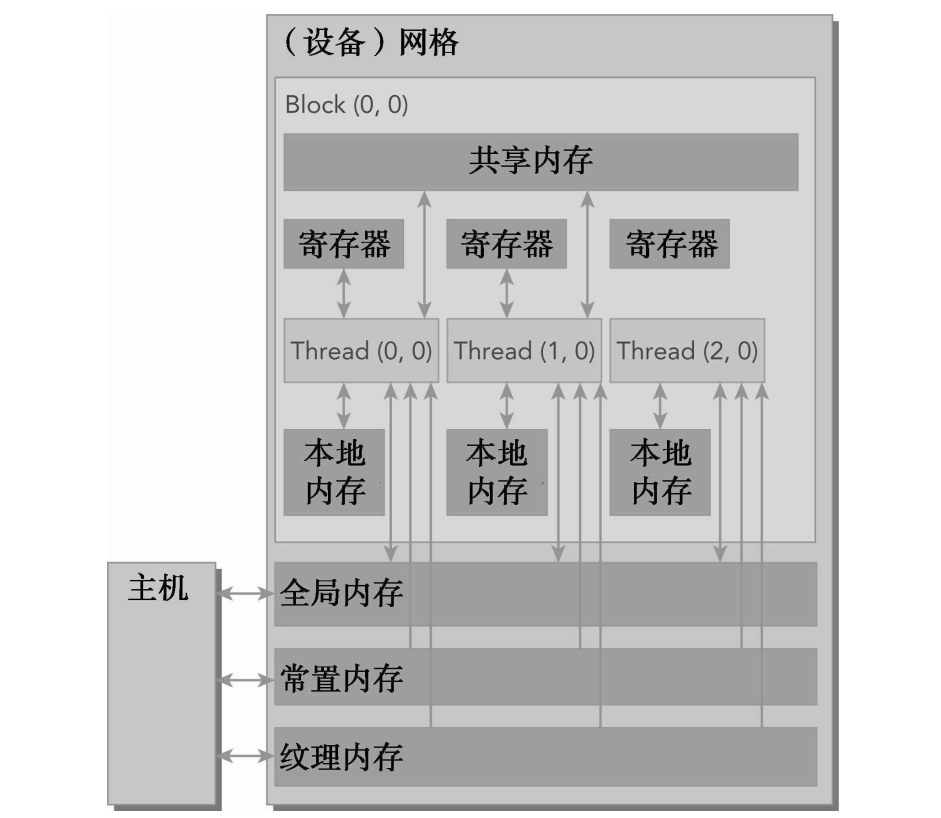
4.1 内存模型
存储器的类型:
- 可编程的:寄存器、共享内存、本地内存、常量内存、纹理内存、全局内存
- 不可编程的:L1 Cache、L2 Cache
一个核函数中的线程都有自己私有的本地内存。一个线程块有自己的共享内存,
所有线程都能访问的读写空间:全局内存
所有线程都能访问的只读空间:常量内存和纹理内存
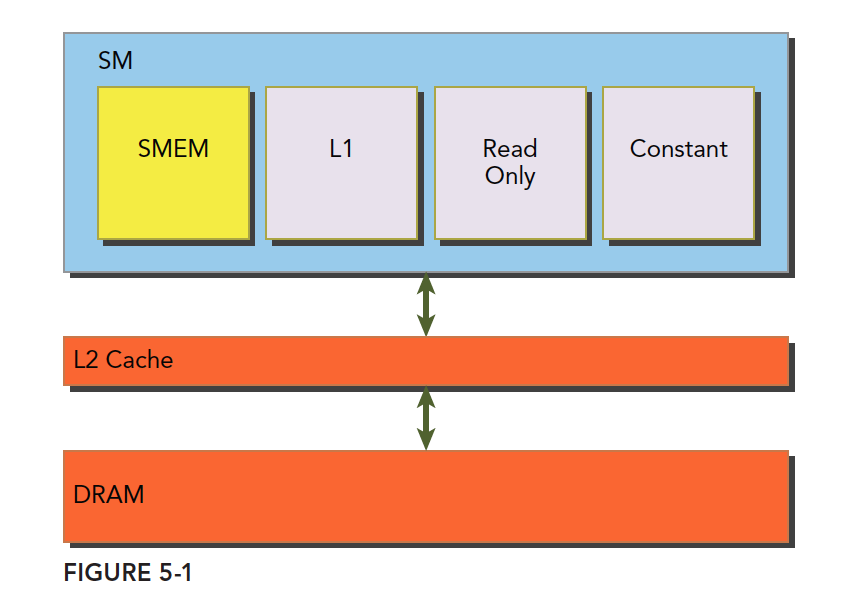
SM上有共享内存,L1一级缓存,ReadOnly 只读缓存,Constant常量缓存。
所有从Dram全局内存中过来的数据都要经过二级缓存,相比之下,更接近SM计算核心的SMEM,L1,ReadOnly,Constant拥有更快的读取速度,SMEM和L1相比于L2延迟低大概20~30倍,带宽大约是10倍。
GPU内存按照类型(物理上的位置)可以分为
- 板载内存
- 片上内存
4.1.1 寄存器register
寄存器是速度最快的内存空间,对于每个线程来说都是私有的,是SM中的稀缺资源
寄存器通常保存被频繁使用的私有变量,
一个线程如果能使用更少的寄存器,SM并发的线程块就越多,效率就越高
如果一个线程里面的变量太多,寄存器完全不够导致寄存器溢出,本地内存就会过来帮忙存储多出来的变量,效率就会大打折扣
nvcc编译器可以采用启发式的方法来最大限度减少寄存器的使用,
在 global 修饰的函数添加 launch_bounds() 修饰符的形式向编译器提供附加信息来辅助这些启发式方法。
1 | __global__ void |
- maxThreadsPerBlock:指定了应用程序启动 MyKernel() 时每个块的最大线程数
- minBlocksPerMultiprocessor:可选,指定了每个多处理器驻留块的最小数
也可以用编译选项
1 | -maxrregcount=32 |
4.1.2 缓存
GPU上有4种缓存:
- 一级缓存
- 二级缓存
- 只读常量缓存
- 只读纹理缓存
每个SM都有一个一级缓存,所有SM公用一个二级缓存
4.1.2.1 内存的访问模式
全局内存通过缓存实现加载和存储的过程如下图
核函数运行时需要从全局内存(DRAM)中读取数据,只有128字节和32字节两种粒度
具体是到底是32还是128还是要看访问方式:
- 使用一级缓存:128字节
- 不使用一级缓存:32字节
原因:当一个SM中正在被执行的某个线程需要访问内存,那么,和它同线程束的其他31个线程也要访问内存,这个基础就表示,即使每个线程只访问一个字节,那么在执行的时候,只要有内存请求,至少是32个字节
4.1.2.2 内存对齐和合并
优化内存的时候,我们要最关注的是以下两个特性
- 对齐内存访问
- 合并内存访问
当一个内存事务(读)的首个访问地址是缓存粒度(32或128字节)的倍数的时候:比如二级缓存32字节的偶数倍64,128字节的偶数倍256的时候,
这个时候被称为对齐内存访问,非对齐访问就是除上述的其他情况,非对齐的内存访问会造成带宽浪费。
当一个线程束内的线程访问的内存都在一个内存块里的时候,就会出现合并访问。
编译器禁用一级缓存的选项是:
1 | -Xptxas -dlcm=cg |
编译器启用一级缓存的选项是:
1 | -Xptxas -dlcm=ca |
启用一级缓存后,当SM有全局加载请求会首先通过尝试一级缓存,如果一级缓存缺失,则尝试二级缓存,如果二级缓存也没有,那么直接DRAM。
4.1.2.3 缓存加载
1.对齐合并的访问,利用率100%

2.对齐的,但是不是连续的,每个线程访问的数据都在一个块内,利用率100%

3.数据横跨两个块,连续非对齐的,就要两个128字节的事务来完成

4.所有线程请求同一个地址,利用率$ {128} = $ 3.125%

5.每个线程束内的线程请求的都是不同的缓存行内

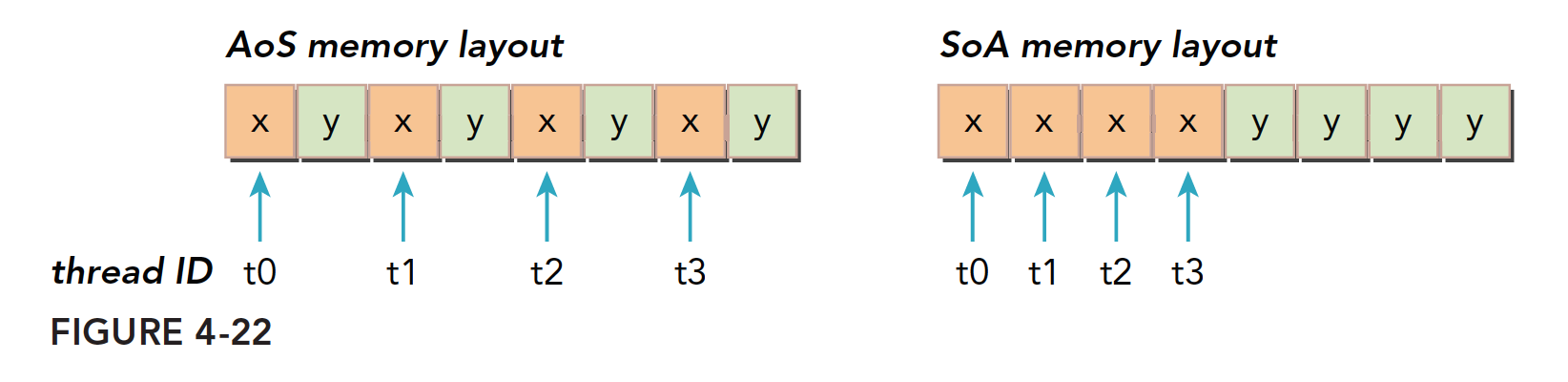
4.1.2.4 数组结构体和结构体数组
结构体数组SoA:
1 | struct A{ |
数组结构体AoS:
1 | struct A a[N]; |
CUDA对细粒度数组是非常友好的,但是对粗粒度如结构体组成的数组就不太友好了
比如当一个线程要访问结构体中的某个成员的时候,当三十二个线程同时访问的时候,SoA的访问就是连续的,而AoS则是不连续:
4.1.3 本地内存
存放在本地内存中的变量有以下几种:
- 使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地数组或者结构体
- 任何不满足核函数寄存器限定条件的变量
本地内存实质上是和全局内存一样在同一块存储区域当中的,其访问特点——高延迟,低带宽。
对于2.0以上的设备,本地内存存储在每个SM的一级缓存,或者设备的二级缓存上。
4.1.4 共享内存
共享内存的速度和L1 Cache一样,但要注意,不要过量使用共享内存,会导致SM上的活跃线程束变少。
SM中的一级缓存,和共享内存共享一个64k的片上内存,通过如下语句设置比例:
1 | cudaError_t cudaFuncSetCacheConfig(const void * func,enum cudaFuncCache); |
cudaFuncCache参数可选如下配置:
1 | cudaFuncCachePreferNone//无参考值,默认设置 |
4.1.4.1 共享内存的分配
共享内存通过关键字:
1 | __shared__ |
声明一个二维浮点数共享内存数组的方法是:
1 | __shared__ float a[size_x][size_y]; |
这里的size_x,size_y和声明c++数组一样,要是一个编译时确定的数字,不能是变量。
如果想动态声明一个共享内存数组,可以使用extern关键字,并在核函数启动时添加第三个参数。
声明:
1 | extern __shared__ int tile[]; |
在执行上面这个声明的核函数时,使用下面这种配置:
1 | kernel<<<grid,block,isize*sizeof(int)>>>(...); |
动态共享内存数组只支持一维!!!!!!
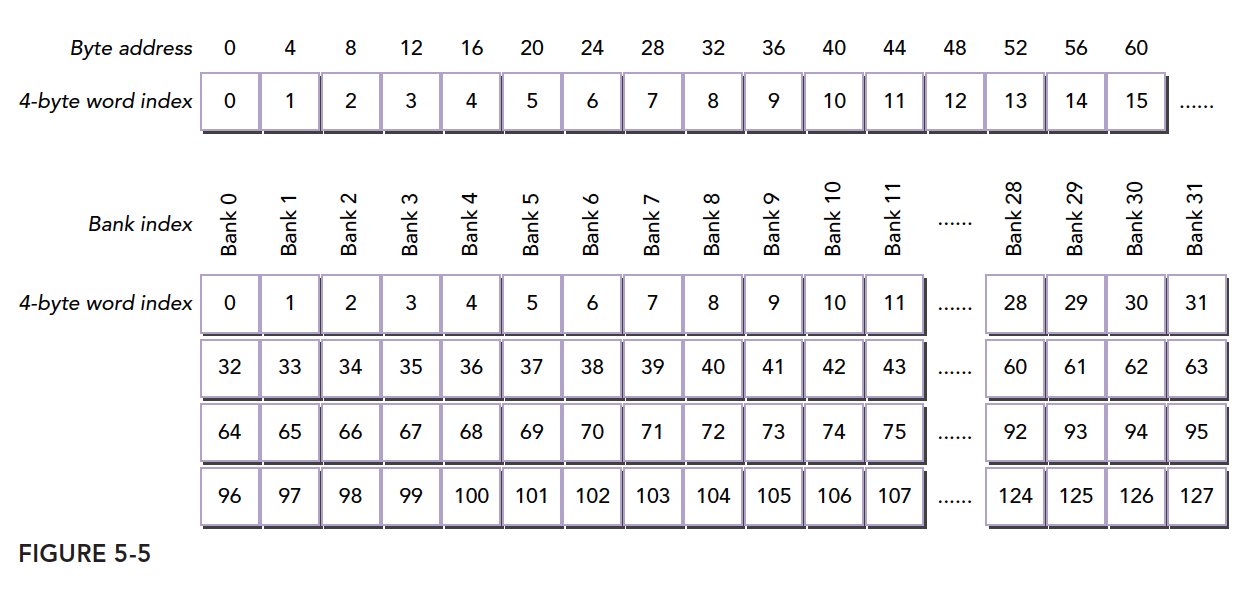
4.1.4.2 存储体冲突
存储体:共享内存被分为32个同样大小的内存模型
内存存储体的宽度随设备计算能力不同而变化,有以下两种情况:
2.x计算能力的设备,为4字节(32位)
3.x计算能力的设备,为8字节(64位)
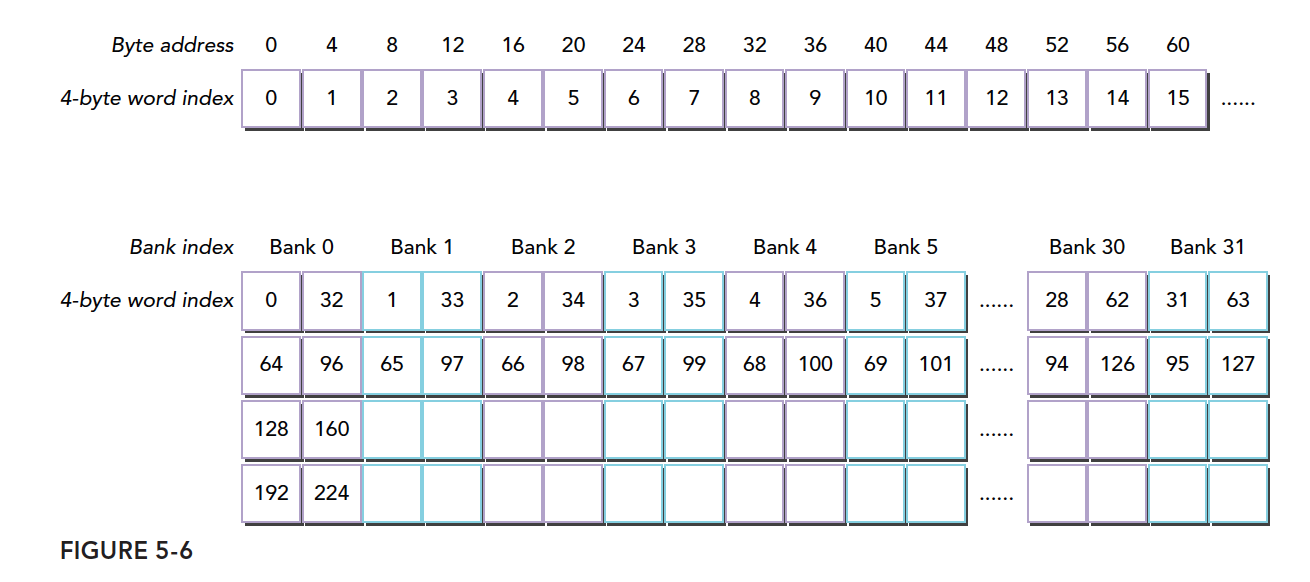
在共享内存中,当多个地址请求落在相同的内存存储体上(同一个存储体的同一列)时,就会发生存储体冲突
注意这里是说访问同一个存储体,而不是同一个地址,访问同一个地址不存在冲突(广播形式)
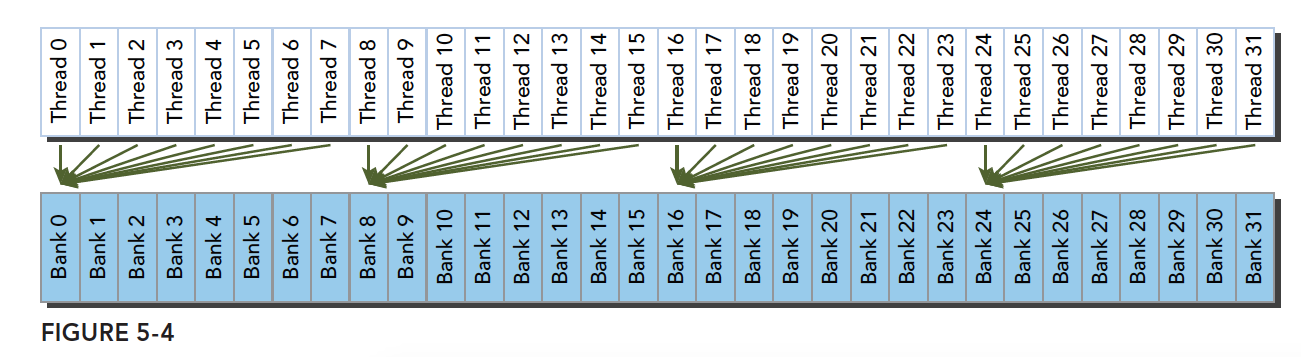
线程束访问共享内存的时候有下面3种模式:
- 并行访问,多地址访问多存储体
- 串行访问,多地址访问同一存储体
- 广播访问,单一地址读取单一存储体
最优访问模式(并行不冲突): 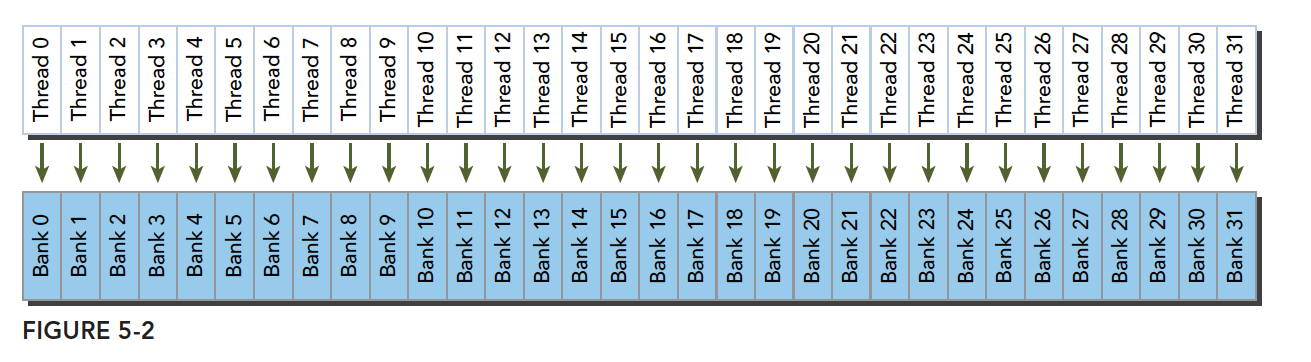
不规则的访问模式(并行不冲突):
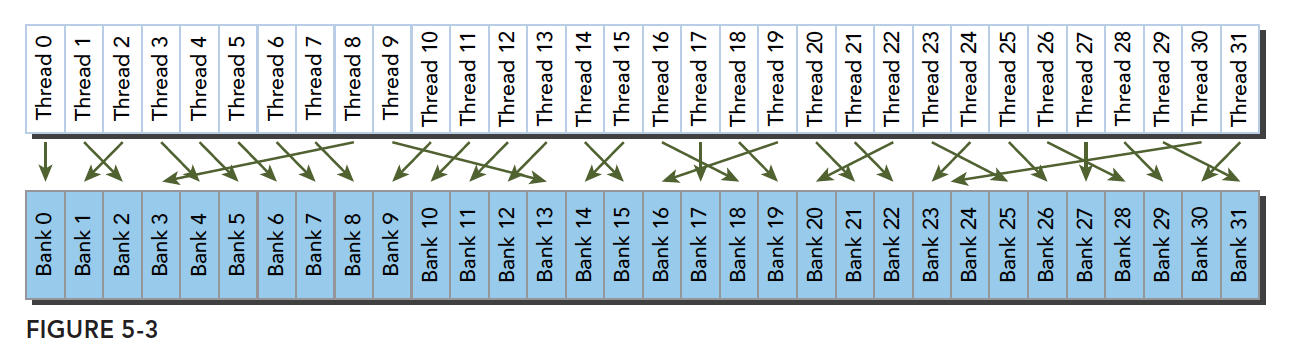
不规则的访问模式(并行可能冲突,也可能不冲突)
4.1.4.3 冲突避免——内存填充
这里我们假设共4个存储体(实际是32个)
1 | __shared__ int a[5][4]; |
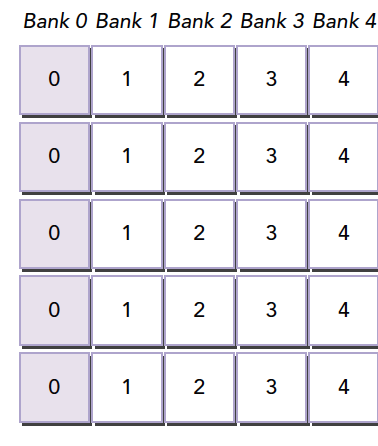
假设5个线程访问第一个存储体的五个数据,就会发生5线程冲突
当我们把声明改为:
1 | __shared__ int a[5][5]; |
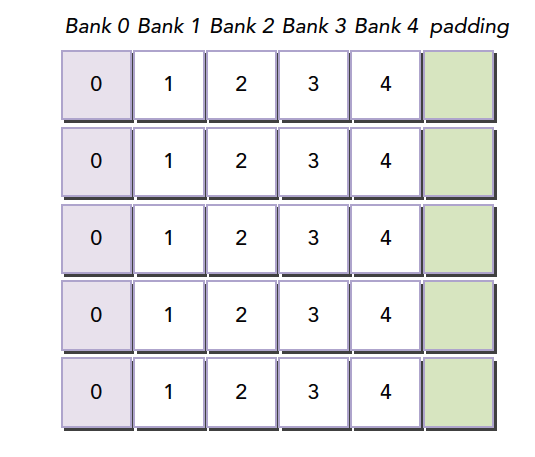
因为我们的存储体只有4个,每一行有5个元素,所以就要发生错位
所有元素都错开了,就不会出现冲突了
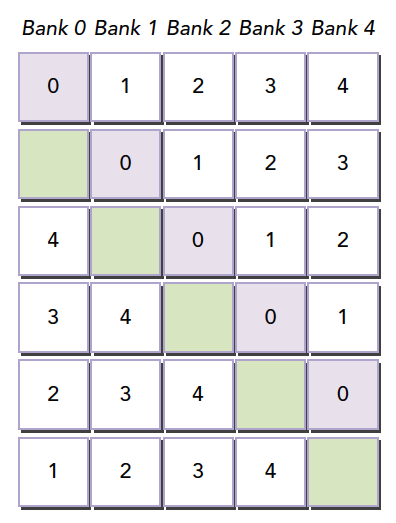
4.1.4.4 数据分布
在CPU中,如果用循环遍历二维数组,我们倾向于内层循环对应x,因为这样的访问方式在内存中是连续的,因为CPU的内存是线性存储的。
但是GPU的共享内存并不是线性的,而是二维的,分为不同的存储体
补充:对于一个二维的线程块,线程束是怎么进行划分的?
答:顺着x方向切割,说白了就是不要一个线程束中访问一列共享内存,而是要访问一行。
4.1.4.5 矩阵转置
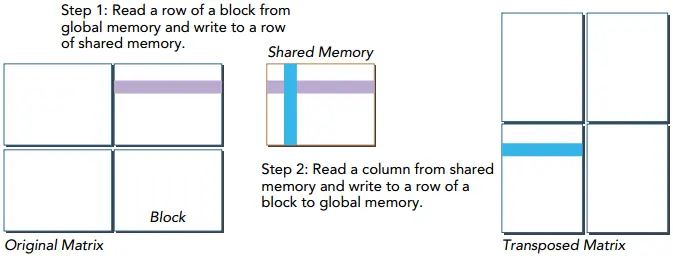
- 读:原矩阵行进行读取,请求的内存是连续的,可以进行合并访问
- 写:写到转置矩阵的列中,访问是交叉的
不管是按哪种顺序读取,写入的顺序永远和他相反。
上图读取的时候就可以进行合并访问,但是写入就不可以,所以引入共享内存可以极大的加速计算效率。
4.1.5 常量内存
常量内存使用:
1 | __constant__ |
常量内存需要在全局范围内声明,只可以声明64k的常量内存
常量内存,被主机端初始化后不能被核函数修改,初始化函数如下:
1 | cudaError_t cudaMemcpyToSymbol(const void* symbol,const void *src,size_t count); |
如果不同的线程取不同地址的数据,常量内存就不那么好了,因为常量内存的读取机制是:一次读取会广播给所有线程束内的线程。
4.1.5.1 只读缓存
只读缓存拥有从全局内存读取数据的专用带宽,不同的设备有不同的只读缓存大小
- 常量缓存对于统一读取(读同一个地址)执行更好
- 只读缓存适合分散读取
使用方法(两种):
1 | __global__ void kernel(float* output, float* input) { |
1 | __global__ void kernel(float* output, const float* __restrict__ input) { |
4.1.6 纹理内存
纹理内存驻留在设备内存中,在每个SM的只读缓存中缓存,纹理内存是通过指定的缓存访问的全局内存,只读缓存包括硬件滤波的支持,
它可以将浮点插入作为读取过程中的一部分来执行,纹理内存是对二维空间局部性的优化。
总的来说纹理内存设计目的应该是为了GPU本职工作显示设计的,但是对于某些特定的程序可能效果更好,比如需要滤波的程序,可以直接通过硬件完成。
4.1.7 全局内存
GPU上最大的内存空间,延迟最高,使用最常见的内存,通过
1 | __device__ |
关键字进行定义,全局内存访问是对齐,也就是一次要读取指定大小(32,64,128)整数倍字节的内存
全局内存有动态分配和静态分配两种类型
静态如下:
1 |
|
注意cudaMemcpyToSymbol和cudaMemcpyFromSymbol
4.2 内存管理
4.2.1 内存的分配和释放
4.2.1.1 内存分配
之前的例子中很多都有cudaMalloc这个函数,不过多赘述,
1 | cudaError_t cudaMalloc(void ** devPtr,size_t count) |
要注意的就是一个二级指针
4.2.1.2 初始化
用法和Memset类似
1 | cudaError_t cudaMemset(void * devPtr,int value,size_t count) |
4.2.1.3 内存释放
1 | cudaError_t cudaFree(void * devPtr) |
4.2.2 内存传输
1 | cudaError_t cudaMemcpy(void *dst,const void * src,size_t count,enum cudaMemcpyKind kind) |
参数:dst目标地址,src原始地址,拷贝的内存大小,传输类型,
传输类型包括以下几种:
- cudaMemcpyHostToHost(这个不常用...我无法理解)
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
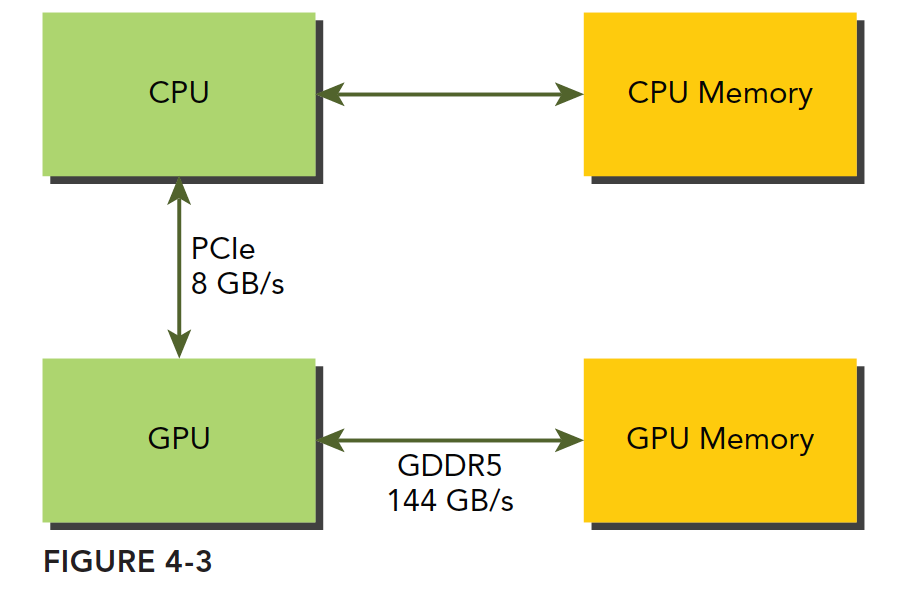
GPU的内存理论峰值带宽非常高,对上图有144 GB/s,但是CPU和GPU之间的PCIe总线速度才8GB/s
所以要尽量避免频繁的内存传输
4.2.3 固定内存
主机内存基本都是采用分页式管理,应用程序分配到的一大块内存空间可能不在连续的页上,应用通过虚拟的内存地址使用这一大块内存。
而操作系统可能随时会更换物理地址的页,从主机传输到设备上的时候,如果此时发生了页面移动,对于传输操作来说是致命的,
所以在数据传输之前,CUDA驱动会锁定页面,或者直接分配固定的主机内存
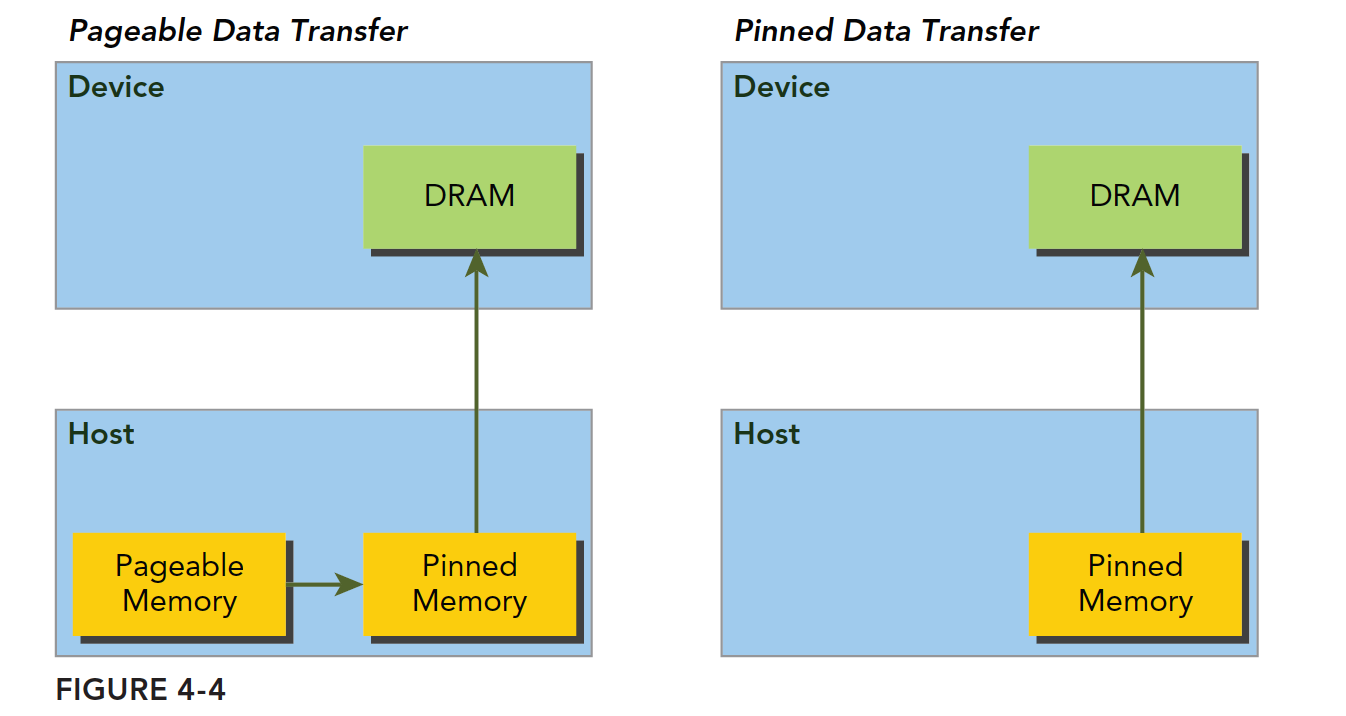
左边是正常分配内存,传输过程是:锁页-复制到固定内存-复制到设备
右边时分配时就是固定内存,直接传输到设备上。
下面函数用来分配和释放固定内存:
1 | cudaError_t cudaMallocHost(void ** devPtr,size_t count) |
1 | cudaError_t cudaFreeHost(void *ptr) |
这些内存是页面锁定的,可以直接传输到设备,使得传输效率就变高了很多
4.2.4 零拷贝内存
之前我们了解到的东西都是:主机和设备不能相互访问各自内存
但是,零拷贝内存的出现打破了这个理论
GPU线程可以直接访问零拷贝内存,这部分内存在主机内存里面
零拷贝内存是固定内存,不可分页。可以通过以下函数创建零拷贝内存:
1 | cudaError_t cudaHostAlloc(void ** pHost,size_t count,unsigned int flags) |
最后一个标志参数,可以选择以下值:
- cudaHostAllocDefalt:函数会与cudaMallocHost一样的用途
- cudaHostAllocPortable:返回能被所有CUDA上下文使用的固定内存
- cudaHostAllocWriteCombined:返回写结合内存,在某些设备上这种内存传输效率更高
- cudaHostAllocMapped:返回零拷贝内存
零拷贝内存虽然不需要显式的传递到设备上,但是设备还不能通过pHost直接访问对应的内存地址,
设备需要访问主机上的零拷贝内存,需要先获得另一个地址帮助访问
1 | cudaError_t cudaHostGetDevicePointer(void ** pDevice,void * pHost,unsigned flags); |
此处flag必须设置为0
零拷贝内存可以当做比设备主存储器更慢的一个设备,因为每次都要经过PCIe
4.2.5 统一内存管理
这玩意儿不好用,做一下了解
统一内存寻址可以实现设备内存和主机内存被映射到同一虚拟内存地址中
1 | cudaMallocManaged((float**)&a_d,nByte) |
在表面上看在设备和主机端都能访问,但是内部过程和我们前面手动copy过来copy过去是一样的,也就是memcopy是本质,而这个只是封装了一下
使用统一内存还是手动控制,运行速度差不多。但是实验表明,手动控制还是要优于统一内存管理
4.2.6 内存栅栏
内存栅栏能保证栅栏前的内核内存写操作对栅栏后的其他线程都是可见的,
有以下三种栅栏:块,网格,系统。
线程块内:保证同一块中的其他线程对于栅栏前的内存写操作可见
1 | void __threadfence_block(); |
网格级内存栅栏:挂起调用线程,直到全局内存中所有写操作对相同的网格内的所有线程可见
1 | void __threadfence(); |
系统级栅栏:夸系统,包括主机和设备,
1 | void __threadfence_system(); |
4.2.7 volatile禁止编译器优化
volatile声明的变量始终在全局内存中
1 | volatile int *pos; |
五、线程束洗牌指令
洗牌指令(Shuffle Instruction)作用在线程束内,允许两个线程见相互访问对方的寄存器
支持线程束洗牌指令的设备最低也要3.0以上,
这样就为相互访问提供了物理基础,线程束内线程相互访问数据不通过共享内存或者全局内存,使得通信效率高很多
Lane:束内线程,一个线程束内的索引【0,31】
5.1 整型变量洗牌
5.1.1 从特定的线程获取值
1 | int __shfl (int var, int srcLane, int width=warpSize);//width默认为32 |
当width=32时:该线程束内的所有线程从特定的束内线程获取数值
当width≠32时:会把线程束分成若干个大小为 width 的块进行计算
假设 width=16,要得到 2 号线程的 var 值,即 srcLane 值为2,那么 0~15 线程接收 2 号线程的 var 值,而16~32 线程接收 18 号线程的 var 值。
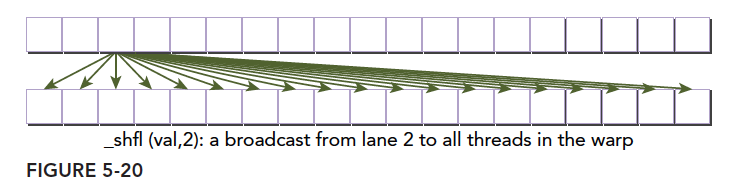
新版本中,__shfl指令已经被弃用,可以用__shfl_sync进行替代
广播:
1 | __global__ void test_shfl_broadcast(int *in,int*out,int const srcLans) |
环移位:
1 | __global__ void shuffleExample() { |
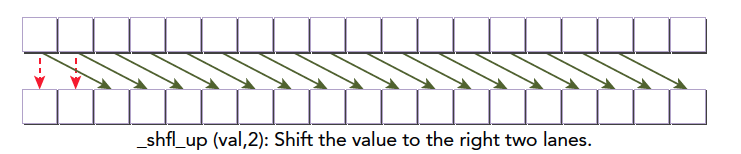
5.1.2 通过平移获取值
1 | int __shfl_up(int var,unsigned int delta,int with=warpSize); |
1 | int __shfl_down(int var,unsigned int delta,int with=warpSize); |
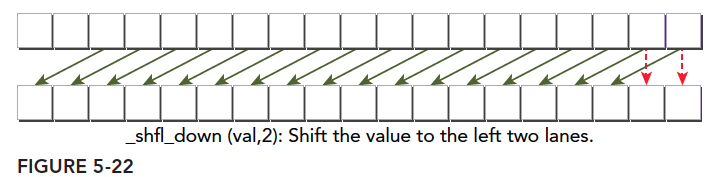
由于是线程编号加减操作,所以没有被索引到的线程保持原值。
5.1.3 通过异或计算获取值
1 | int __shfl_xor(int var, int laneMask, int width=warpSize); |
该指令则是将线程束内的线程号与 laneMask 的值进行异或计算,返回以异或计算结果为编号的线程中 var 的值。
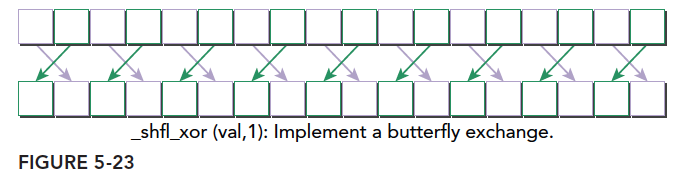
5.2 浮点型变量洗牌
与整型一样,只是通过重载的方式实现了不同的操作,替换var的数据类型为浮点型即可
1 | DataType __shfl_xxx(DataType var, .....) |
六、流
6.1 基本介绍
我们的所有CUDA操作都是在流中进行的,之前没有这个概念,内核函数或者数据传输其实都是在默认流上进行。
默认流:隐式声明的流(空流是没办法进行管理的),默认
非默认流:显式声明的流

CUDA编程典型模式:
- 将输入数据从主机复制到设备上
- 在设备上执行一个内核计算
- 将结果从设备复制回主机

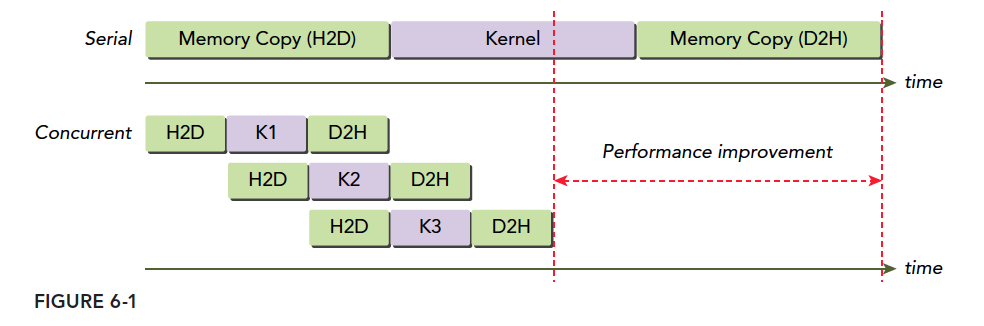
流在CUDA的API调用可以实现流水线和双缓冲技术。
但由于PCIe总线和SM资源是有限的,如果设备已经跑满了,那么我们认为并行流的指令也必须排队等待。
6.2 使用流
6.2.1 核函数的流操作
1 | cudaStream_t stream; |
kernel函数启动后,虽然会立马执行cudaStreamDestory函数,但是并不会立即停止流,而是等待流执行完成。
cudaStreamCreate创建的是阻塞流,默认流也是阻塞流!!!!!
比如:
1 | kernel_1<<<1, 1, 0, stream_1>>>(); //stream_1 |
stream_1 和 stream_2
都是使用cudaStreamCreate创建的流,
三个流都是阻塞的,具体运行步骤如下:
- kernel_1 启动完成并执行,控制权返回主机
- kernel_2 启动完成,控制权返回主机,等待 kernel_1 完毕后才执行
- kernel_3 同理,启动完成后控制权就返回主机,但是需要等待kernel_2执行完成才正式执行
从主机角度,这三个kernel都是异步的,启动后的控制权都会立马还给主机,但是相对GPU而言是串行执行的。
问:如果去掉kernel2的启动代码,kernel3必须等到kernel1执行完成之后才能执行吗?
设备计算资源足够的情况下,
如果设备不支持Hyper-Q时就还是需要等待,
支持Hyper-Q时kernel1与kernel3可以并发执行。
(后文有Hyper-Q的介绍)
创建一个非阻塞流:
1 | cudaError_t cudaStreamCreateWithFlags(cudaStream_t* pStream, unsigned int flags); |
具体可以参考:https://blog.csdn.net/qq_17239003/article/details/78994992
6.2.2 数据的流操作
异步数据传输:
1 | cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count,cudaMemcpyKind kind, cudaStream_t stream = 0); |
可以看到stream默认为0,也就是默认流
注意:异步传输必须使用固定内存页面!!!
1 | cudaError_t cudaMallocHost(void **ptr, size_t size); |
主机虚拟内存中分配的数据在物理内存中是随时可能被移动的,我们必须确保其在整个生存周期中位置不变,这样在异步操作中才能准确的转移数据。
6.2.3 流状态查询
主机端执行此函数,会一直阻塞等待流完成:
1 | cudaError_t cudaStreamSynchronize(cudaStream_t stream); |
cudaStreamQuery则是立即返回,无需阻塞
如果查询的流执行完了,那么返回cudaSuccess否则返回cudaErrorNotReady。
1 | cudaError_t cudaStreamQuery(cudaStream_t stream); |
例:
2
3
4
5
6
7
8
9
int offset = i * bytesPerStream;
cudaMemcpyAsync(&d_a[offset], &a[offset], bytePerStream, streams[i]);
kernel<<grid, block, 0, streams[i]>>(&d_a[offset]);
cudaMemcpyAsync(&a[offset], &d_a[offset], bytesPerStream, streams[i]);
}
for (int i = 0; i < nStreams; i++) {
cudaStreamSynchronize(streams[i]);
}第一个for中循环执行了nStreams个流,每个流中都是“复制数据,执行核函数,最后将结果复制回主机”这一系列操作。
串行和流的示例图如下:
6.3 流调度
从模型上看,所有流之间都是可以同时执行的,但是由于硬件有限,就需要流调度
6.3.1 Fermi架构流
Fermi架构,是16路流并发执行,但是所有流最终都是在单一硬件上执行的,Fermi只有一个硬件工作队列
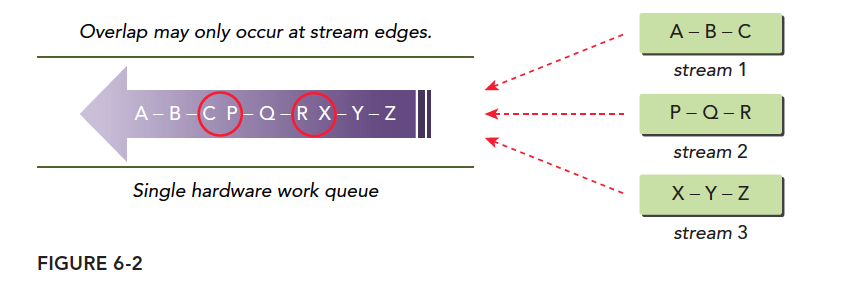
- 执行A,同时检查B是否有依赖关系,当然此时B依赖于A而A没执行完,所以整个队列阻塞
- A执行完成后执行B,同时检查C,发现依赖,等待
- B执行完后,执行C同时检查,发现P没有依赖,如果此时硬件有多于资源P开始执行
- P执行时检查Q,发现Q依赖P,所以等待
这种执行方式就导致了一种P依赖于B或者A的感觉,实际上不依赖,这就是虚假依赖
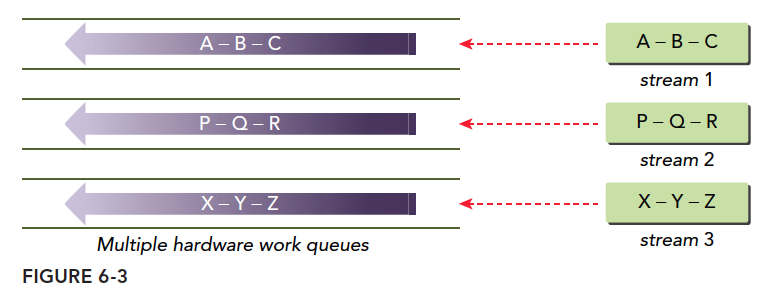
6.3.2 Hyper-Q技术
解决虚假依赖的最好办法就是多个工作队列,Hyper-Q就是这种技术,32个硬件工作队列同时执行多个流,这就可以实现所有流的并发,最小化虚假依赖:
6.4 流的优先级
流可以设置优先级,数字越小的,优先级越高
(优先级只影响核函数,不影响数据传输,高优先级的可以抢占低优先级的)
下面函数创建一个有指定优先级的流:
1 | cudaError_t cudaStreamCreateWithPriority(cudaStream_t* pStream, unsigned int flags,int priority); |
不同的设备有不同的优先级等级,以下函数获得允许的优先级范围:
1 | cudaError_t cudaDeviceGetStreamPriorityRange(int *leastPriority, int *greatestPriority); |
6.5 流事件
流事件用于检测流的执行是否到达指定的操作点
流事件本身也需要作为流插入到流中,通过cudaEventRecord插入
流事件插入流后,当七关联的操作完成后就会在主机端产生一个完成标志
插入流中的事件可以用于主机线程等待此事件完成:cudaEventSynchronize(线程同步)
通常用来记录某个核函数的耗时:
1 | cudaEvent_t start, stop; |
6.6 加速应用
深度优先方式加速应用
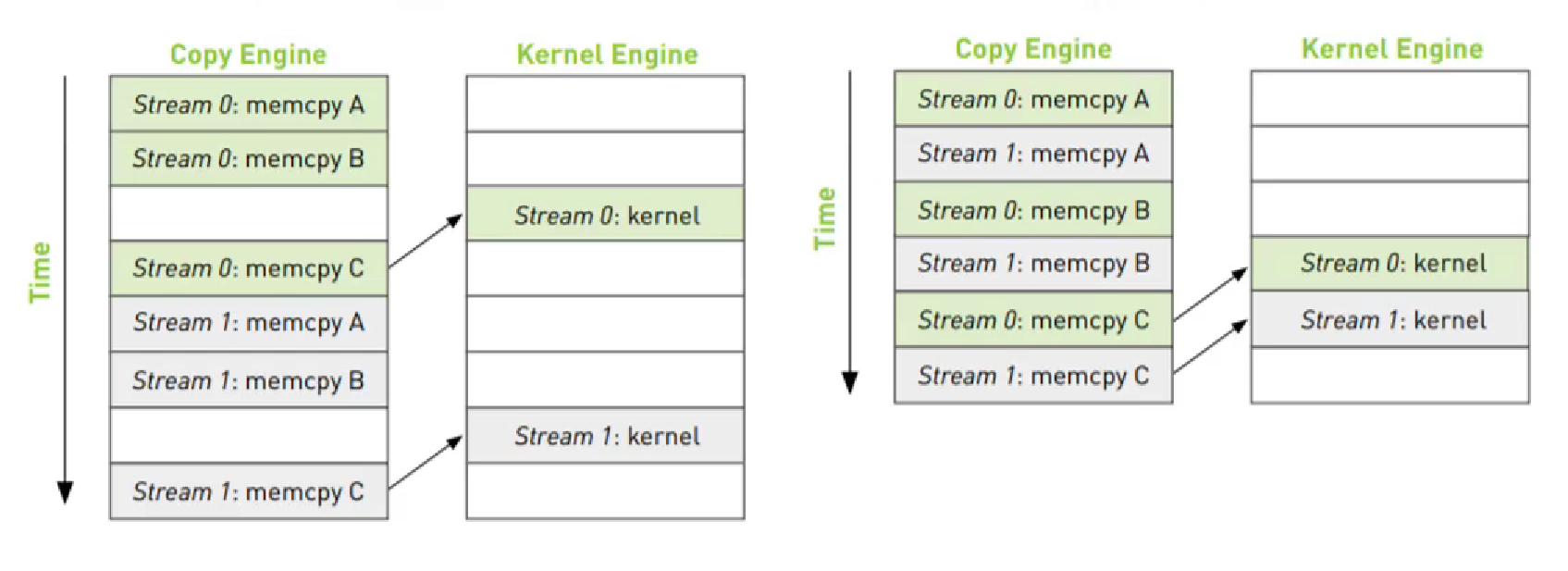
右边的方式在stream 1 进行 memcpy B 的时候就可以利用计算资源为stream 0计算,隐藏时间