一、存储系统
1.1数据存储和排列
1.1.1大小端模式
若有4字节的 int:01 23 45 67 H
多字节数据在内存里一定是占连续的几个字节,01为最高有效字节(MSB),67为最低有效字节(LSB)
大端方式:便于人类阅读

小端方式:便于机器处理

1.1.2边界对齐
假设存储字长为32位,则1个字=32bit,半字=16bit。每次访存只能读/写1个字
边界对齐的方式:

边界不对齐方式:

由于边界不对齐,若要读取半字1,则先要读取第一个字(第一行),再读取第二个字(第二行),最后将半字1-1和半字1-2拼接。所以访问一个字/半字可能需要两次访存
采用边界对齐的方式,访问一个字/半字都只需要一次访存即可。牺牲掉部分空间,但是能加快访存效率。
1.2浮点数的表示和运算
1.2.1前言
定点数的局限性:定点数可以表示的数字范围有限,但我们不能无限制的增加数据长度
1.2.2浮点数的表示
\[ 可以类似于科学计数法,+3.026×10^{+21} \\+/-表示小数点后移/前移多少位 \\浮点数的真值:N=r^E×M \\r为阶码的底,通常为2(二进制) \\E反应浮点数表示范围以及小数点的真是位置 \\M数值部分的位数反应浮点数的精度 \\阶码:常用补码或移码表示的定点整数 \\尾数:常用原码或补码表示的定点小数 \]
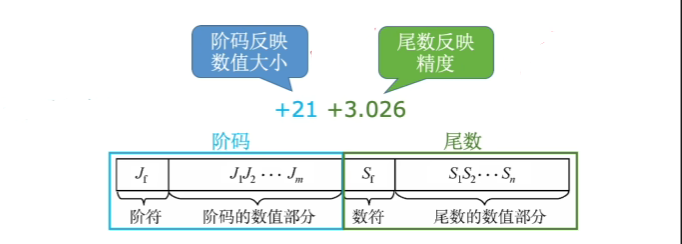
1.2.3浮点数尾数规格化

1.3存储器
1.3.1存储器的层次结构
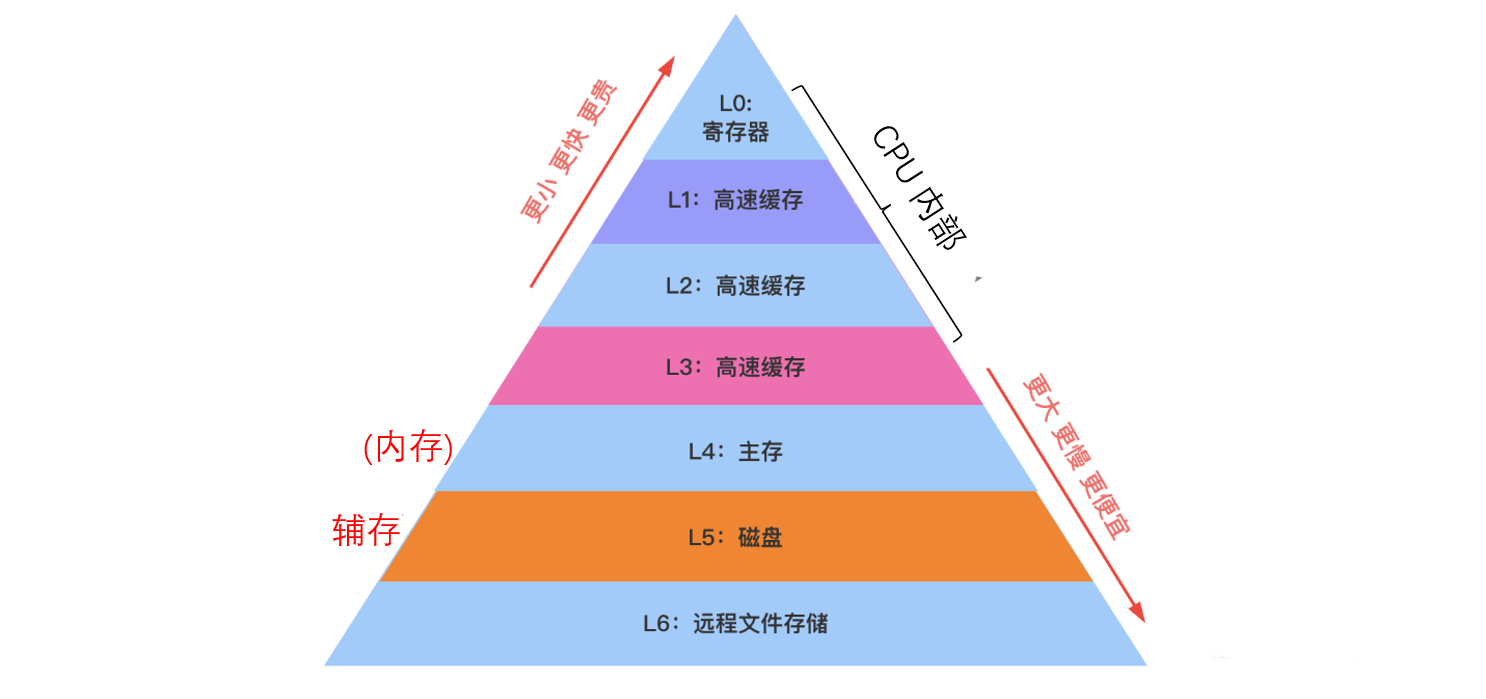
辅存:磁盘、可移动介质
辅存中的数据要调入到主存中才能被CPU访问
缓存:高速缓冲存储器Cache
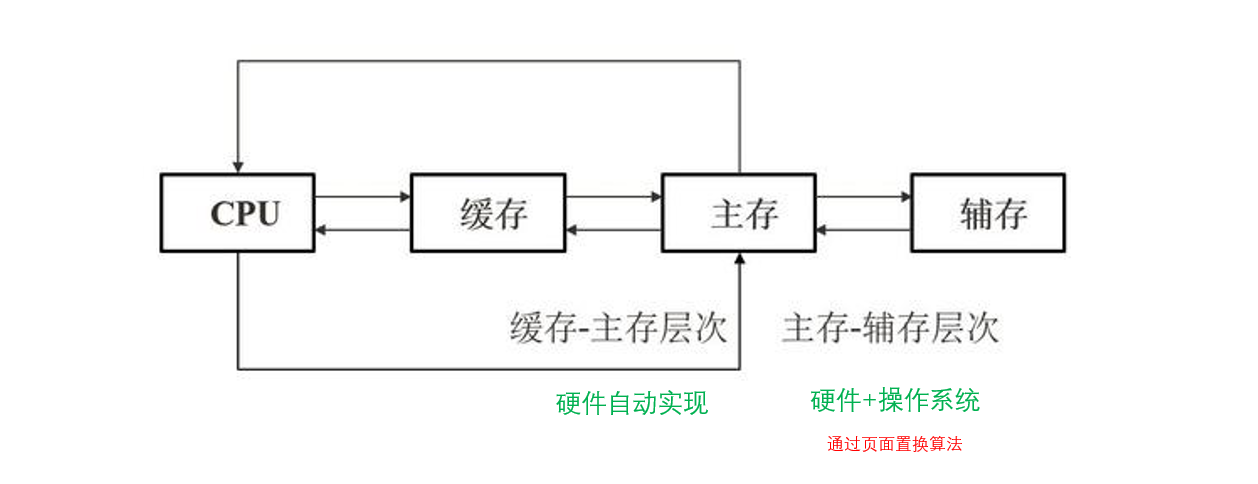
主存-辅存:实现了虚拟存储系统,解决了主存容量不足的问题
Cache-主存:解决了主存与CPU速度不匹配的问题
1.3.2存储器的分类
1.3.2.1按计算机中的层次分类
(1)主存储器。简称主存,又称为内存。用来存放计算机运行期间所需的程序和数据,CPU可以直接随机的对其进行访问,也可以利用Cache间接访问。
(2)辅助存储器。简称辅存,又称外存。用来存放暂时不用的程序和数据,以及一些永久性保存的信息。辅存的内容要调入主存后才能被CPU访问。
(3)高数缓冲存储器。简称Cache,用来存放CPU经常使用的指令和数据,CPU可以高速访问他们。
1.3.2.2按存储介质分类
磁表面存储器(磁盘、磁带)、磁芯存储器、半导体存储器(MOS型存储器、双极型存储器)和光存储器(光盘)
1.3.2.3按信息的可保存性分类
易失性存储器:RAM
非易失性存储器:ROM
1.3.3存储器芯片的基本原理
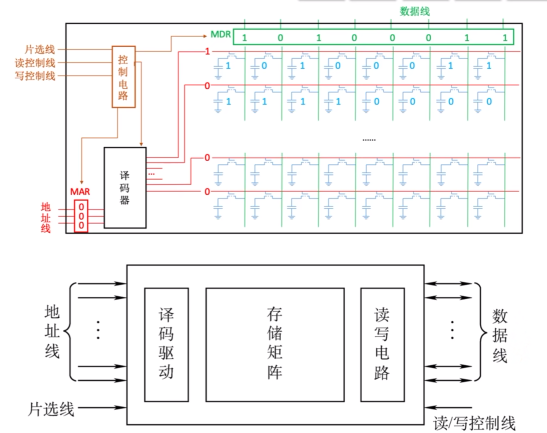 \[
控制电路:等待MAR稳定后才进行译码操作,等待MDR稳定后才进行读写操作
\\片选线
(\overline{CS}或\overline{CE}):一个内存条上可能包含多块存储芯片,用于选择芯片(Chip
Select或Chip Enable)
\\读控制线(\overline{WE}):允许写
\\写控制线(\overline{OE}):允许读
\]
\[
控制电路:等待MAR稳定后才进行译码操作,等待MDR稳定后才进行读写操作
\\片选线
(\overline{CS}或\overline{CE}):一个内存条上可能包含多块存储芯片,用于选择芯片(Chip
Select或Chip Enable)
\\读控制线(\overline{WE}):允许写
\\写控制线(\overline{OE}):允许读
\]
1.3.4DRAM和SRAM
Dynamic Random Access Memory,即动态RAM
Static Random Access Memory,即静态RAM
DRAM用于主存,SRAM用于Cache
DRAM依靠栅极电容实现,SRAM依靠双稳态触发器实现
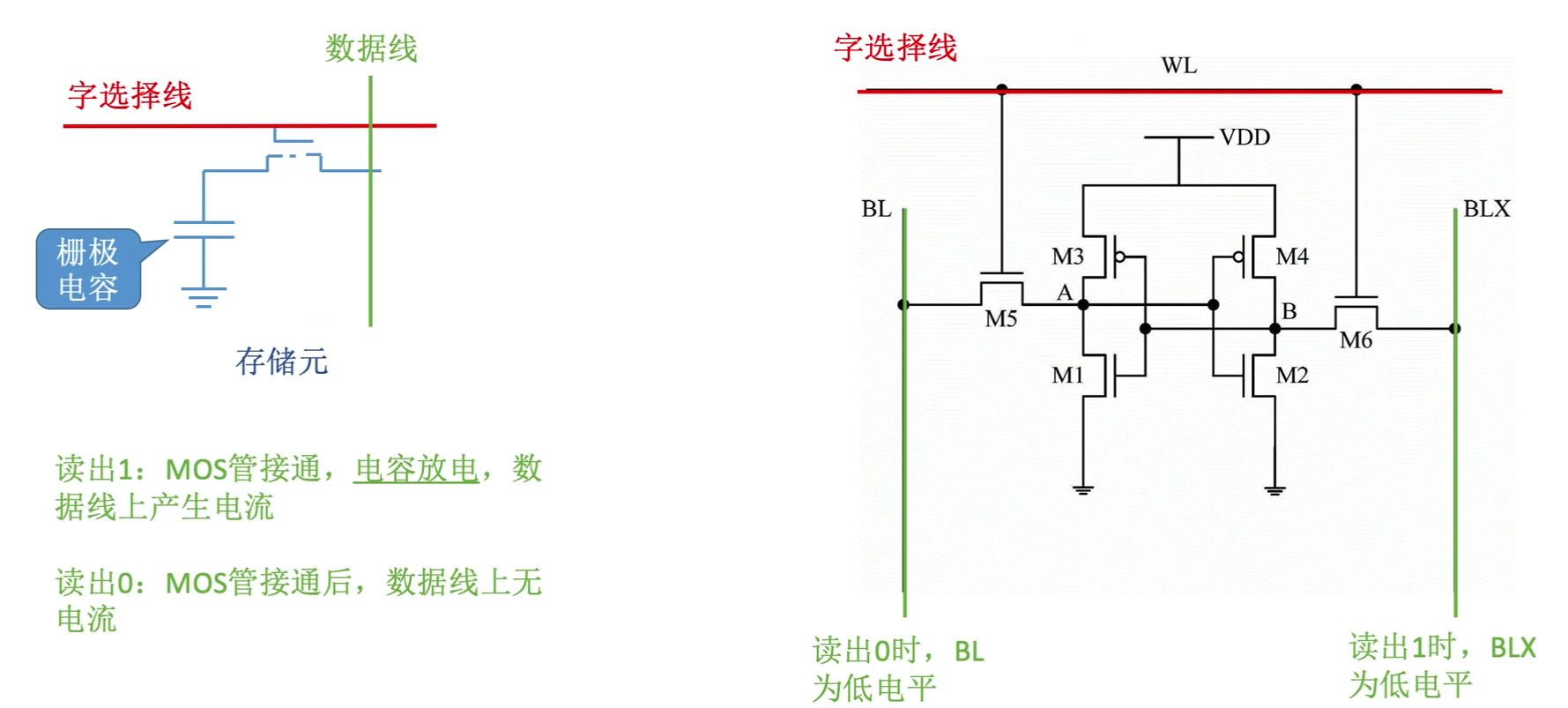
1 | 栅极电容放电信息会被破坏,是破坏性读出。读出后需要“重写”操作,也成为“再生”。 |
由于SRAM不需要重新所以读出速度更快,但是成本更高。并且由于存储元制造更复杂,集成度就更低。
注意:DRAM和SRAM都是易失性的(断电后信息会消失)
1.3.4.1 DRAM的刷新
由于DRAM电容内的电荷只能维持2ms。即便不断电,2ms后信息也会消失,所以要不断的进行刷新(充电)
1.3.5 ROM
ROM芯片--非易失,断电后数据仍然可以保存
1 | MROM:掩模式只读存储器(厂家按客户需求在生产过程中写入,之后不可重写) |
计算机启动时,主存RAM没有任何指令,所以需要主板上的BIOS芯片(ROM)存储了"自举装入程序",负责引导装入操作系统
1.3.6 内存扩展
1.3.6.1 位扩展-增加主存的存储字长
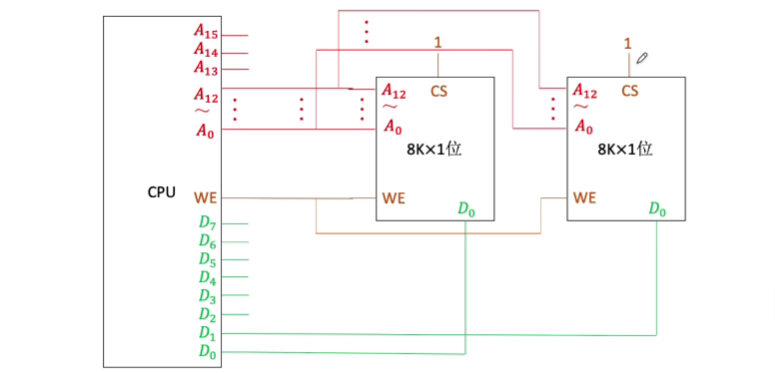
以此类推,拓展为8位,连接方式如下:
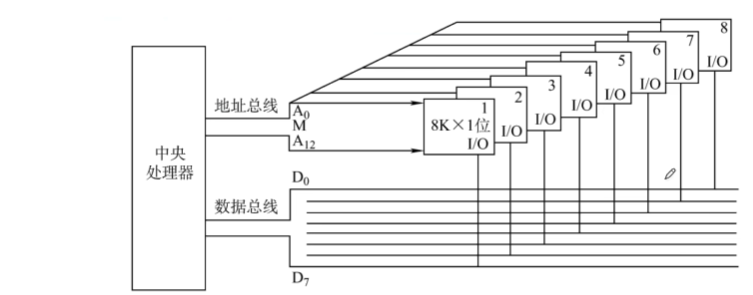
8片8Kx1位的存储芯片 -> 8Kx8位的存储器,容量为8KB(64Kbit)
1.3.6.2 字扩展-增加主存的存储字数
利用片选使能线进行,(1-2译码器),利用A13的两种状态进行选择
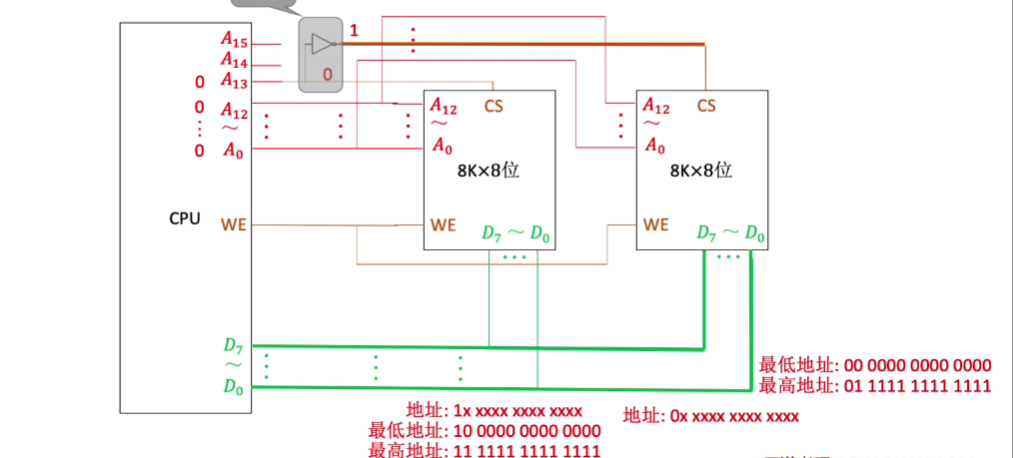
利用2-4译码器进行扩展:
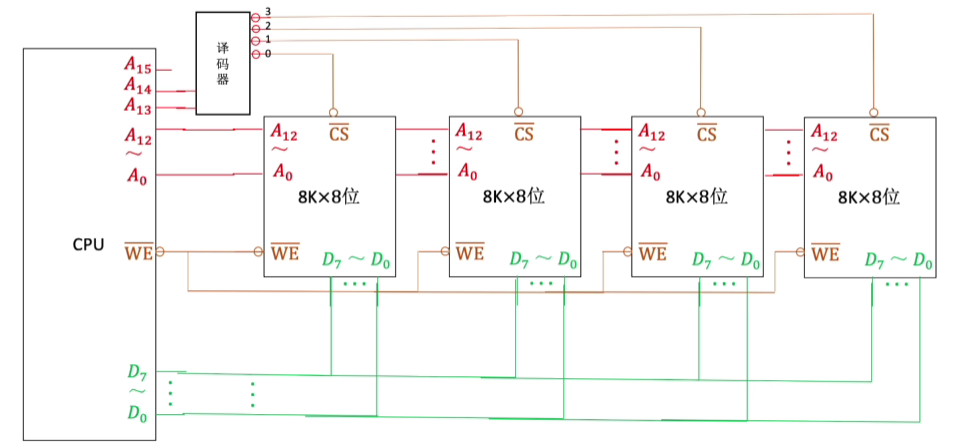
1.3.6.3 字位同时扩展
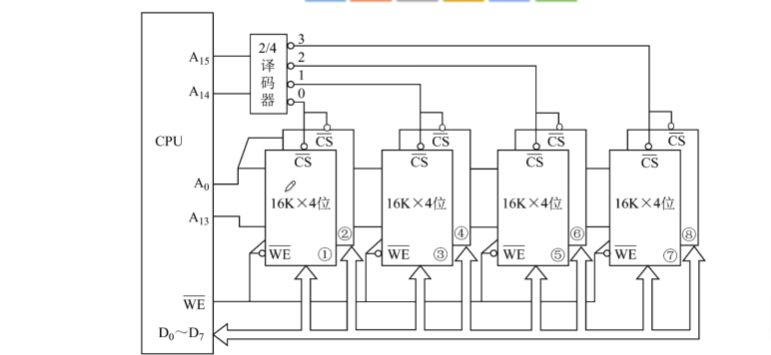
1.4 Cache
1.4.1 Cache的基本概念和原理
1.4.1.0 概念理解
CPU需要从主存一条一条地读取指令,CPU处理速度很快,内存(主存)的读写速度很慢,导致速度不匹配,执行效率就会很低,因此引入Cache
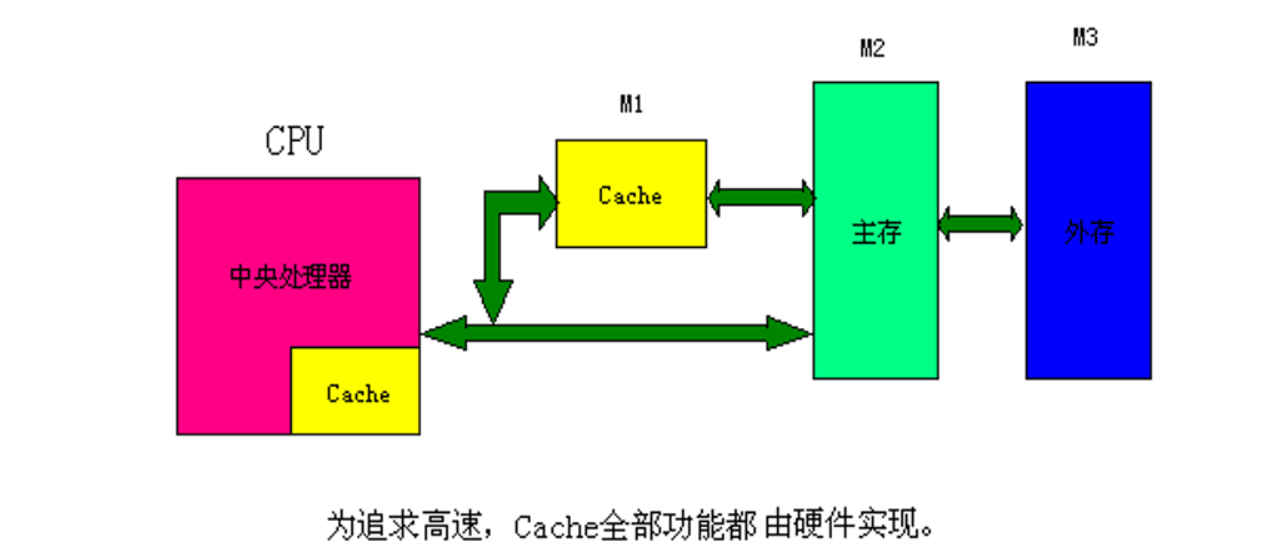 Cache的读写速度很快,可以缓和速度矛盾
Cache的读写速度很快,可以缓和速度矛盾
空间局限性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是相邻的
时间局限性:在最近的未来要用到的信息,很可能是现在正在使用的信息
根据两个原理可以发现,可以把CPU目前访问地址"周围"的部分数据放到Cache中。
1.4.1.1性能分析
\[ 设t_c为访问一次Cache所需时间,t_m为访问一次主存锁需要的时间\\ 命中率H:CPU访问的信息已在Cache中的概率\\ 缺失率M=1-H\\ 系统的平均访问时间t为:\\ t=Ht_c+(1-H)(t_c+t_m) \]
上述例子CPU会优先访问Cache,若Cache missed(未命中)再访问主存
还存在一种CPU同时访问Cache和主存,若Cache命中则立即停止访问主存的方式 \[ t=Ht_c+(1-H)t_m\\ \]
1.4.1.2数据交换
将主存的存储空间进行"分块",如:每1KB为一块,主存和Cache之间以"块"为单位进行数据交换
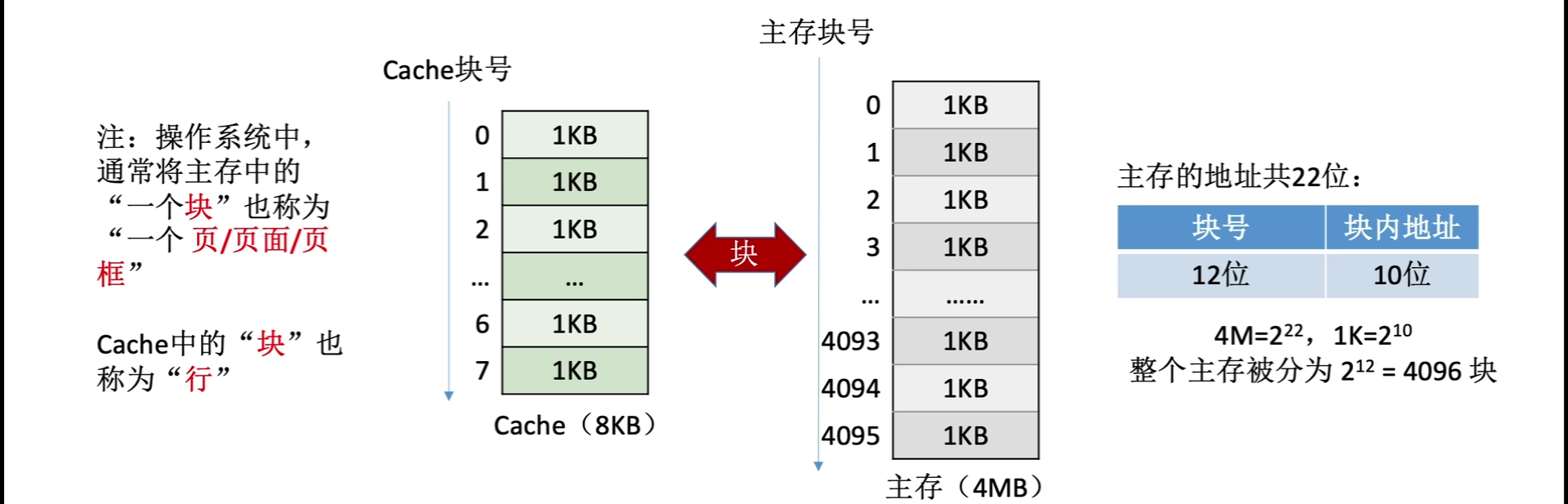
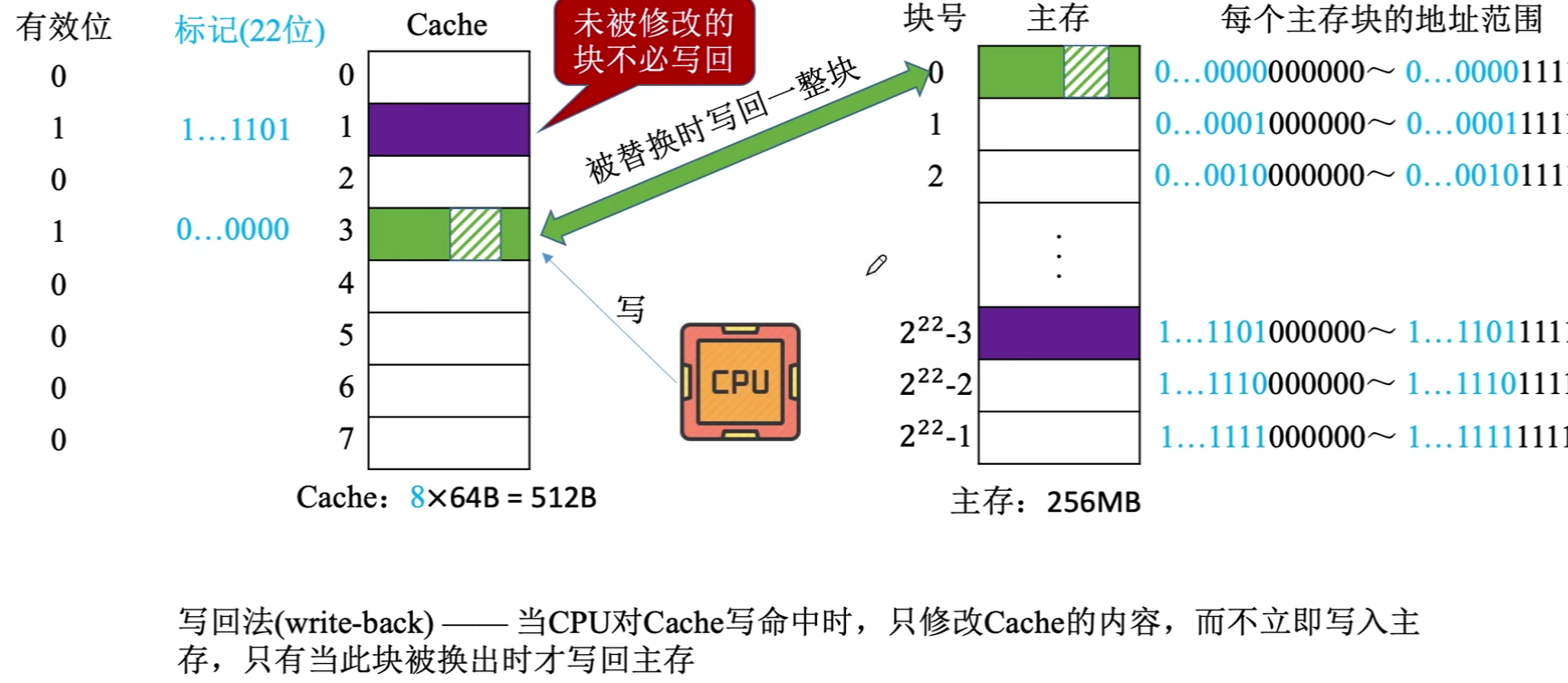
注意:每次被访问的主存块,一定会被立即调入Cache
1.4.1.3Cache和主存的映射方式
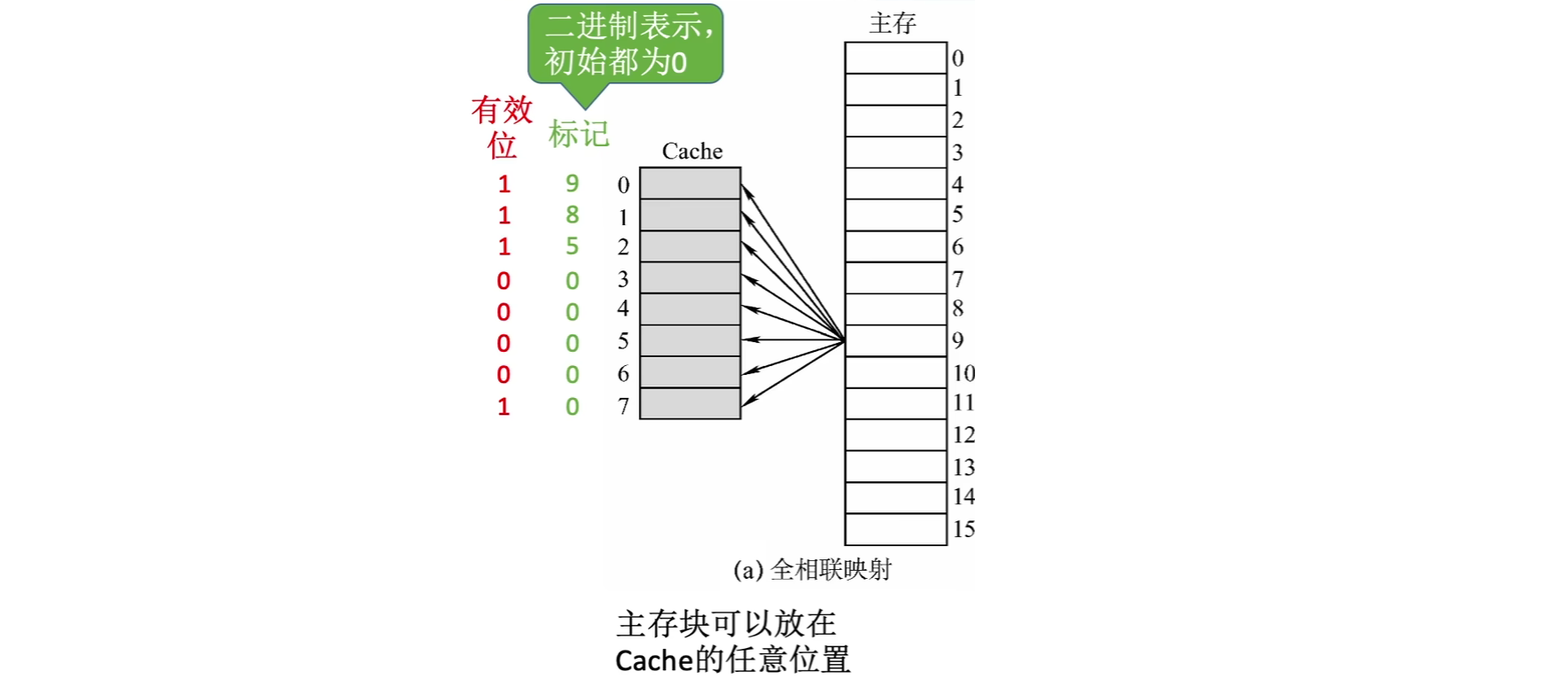
(1)全相联映射(随意放)
标记:记录主存块的索引
 \[
假设某个计算机内存地址空间大小为256MB,按字节编址,其数据Cache有8个Cache行(即Cache块),行长为64B\\
256MB=2^{28}B\\
默认一个存储单元为1字节(1B)因此有2^{28}个地址\\
因此,块内地址为6位,主存块号有22位
\] 访存过程:
\[
假设某个计算机内存地址空间大小为256MB,按字节编址,其数据Cache有8个Cache行(即Cache块),行长为64B\\
256MB=2^{28}B\\
默认一个存储单元为1字节(1B)因此有2^{28}个地址\\
因此,块内地址为6位,主存块号有22位
\] 访存过程:
①主存地址的前22位对比Cache中所有块的标记
②若标记匹配且有效位为1,则Cache命中,访问块内地址单元
③若未命中则正常进行访问主存
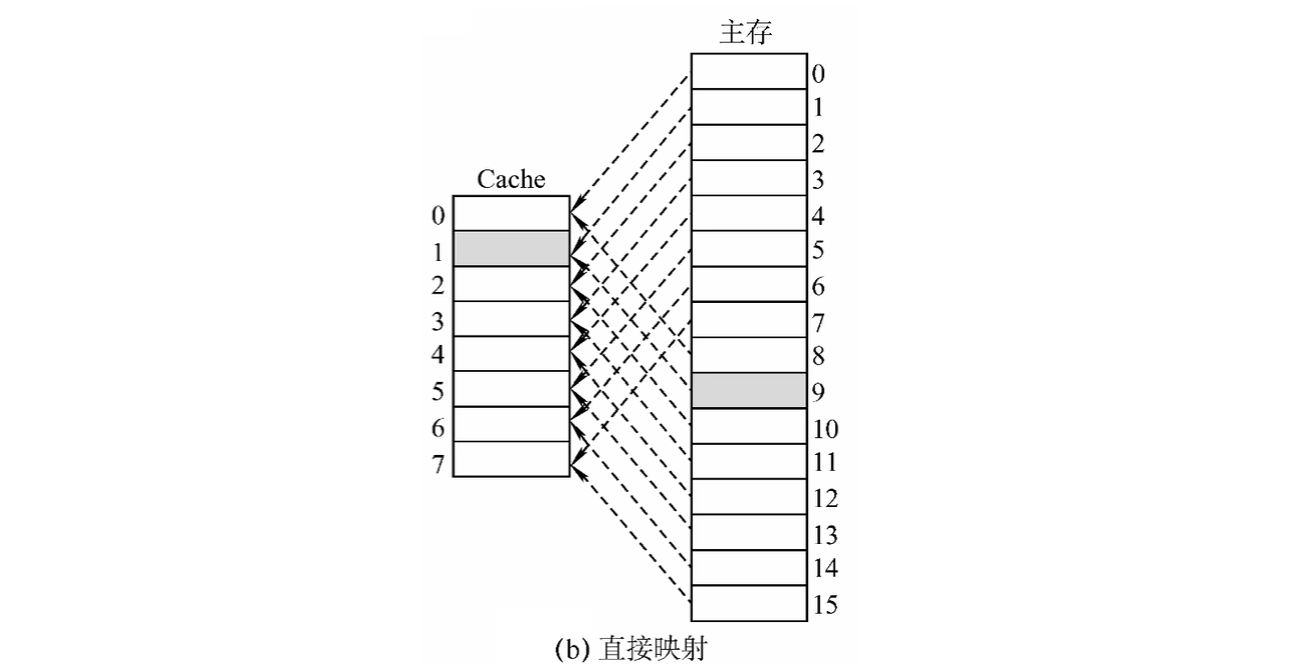
(2)直接映射
每个主存块只能放到一个特定的位置: \[
Cache块号=主存块号\%Cache总块数
\] 
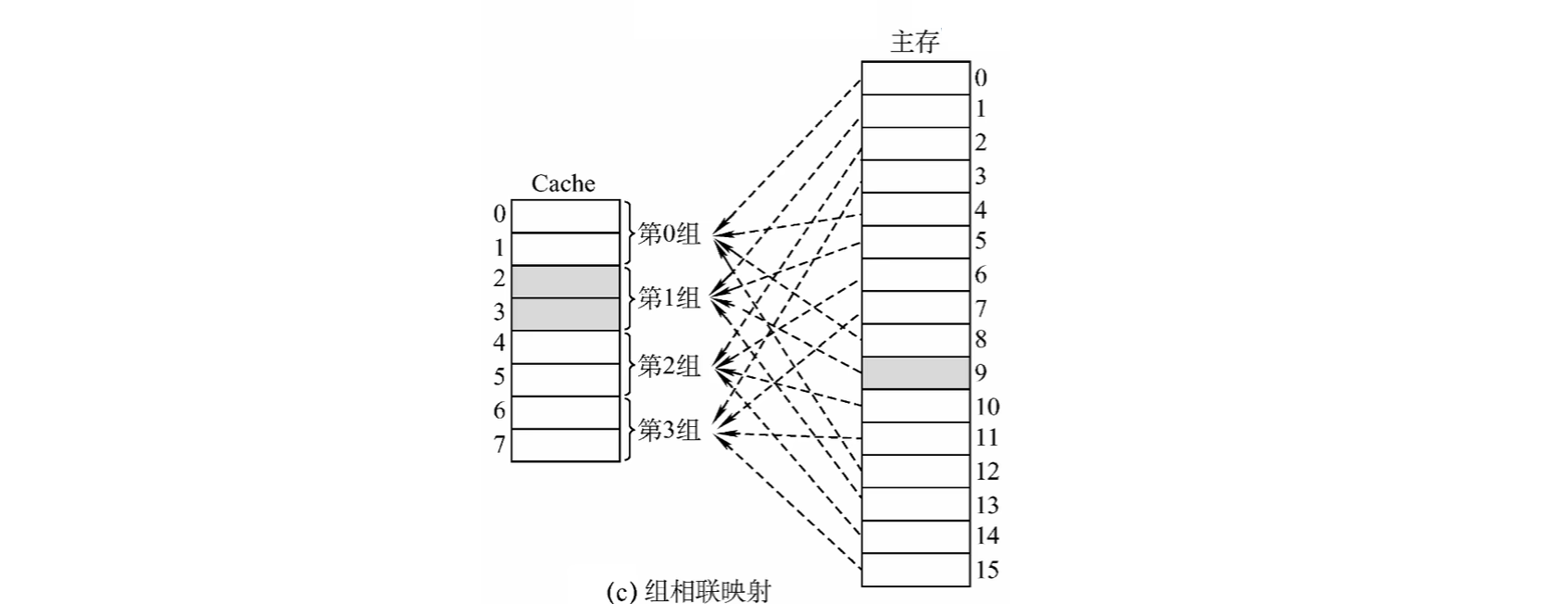
(3)组相联映射
Cache块氛围若干组,每个主存块可以存放到特定分组的任意一个位置 \[
组号=主存块号\%分组数
\] 
1.4.2 替换算法
1.4.2.1随机算法(RAND)
若Cache已满,则随机选择一块进行替换
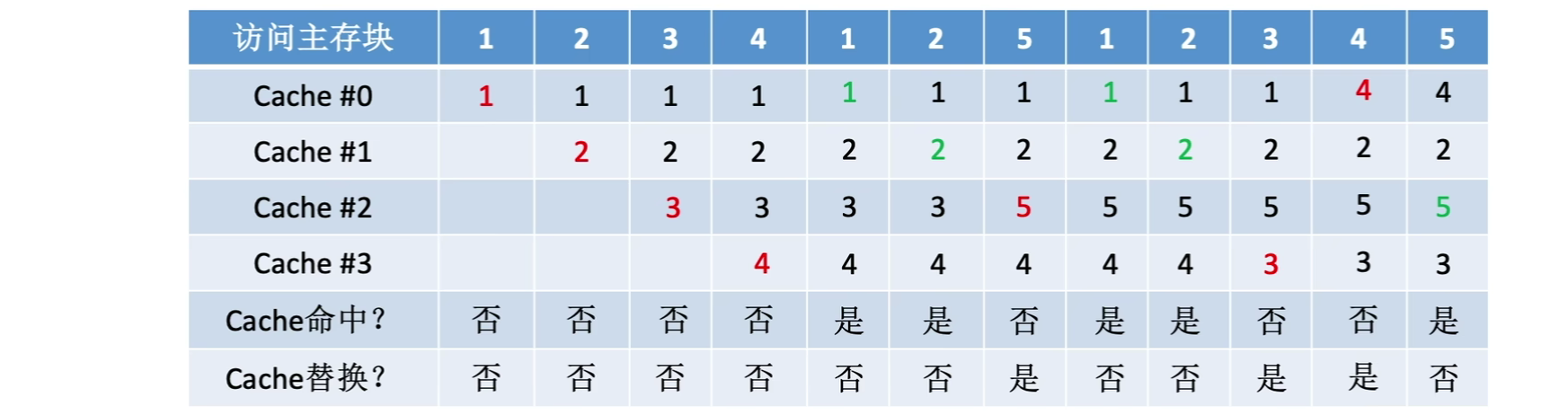
随机算法实现简单,但是没考虑局部性,命中率低,实际效果很不稳定
1.4.2.2先进先出算法(FIFO)
若Cache已满,则替换最先被调入的Cache块
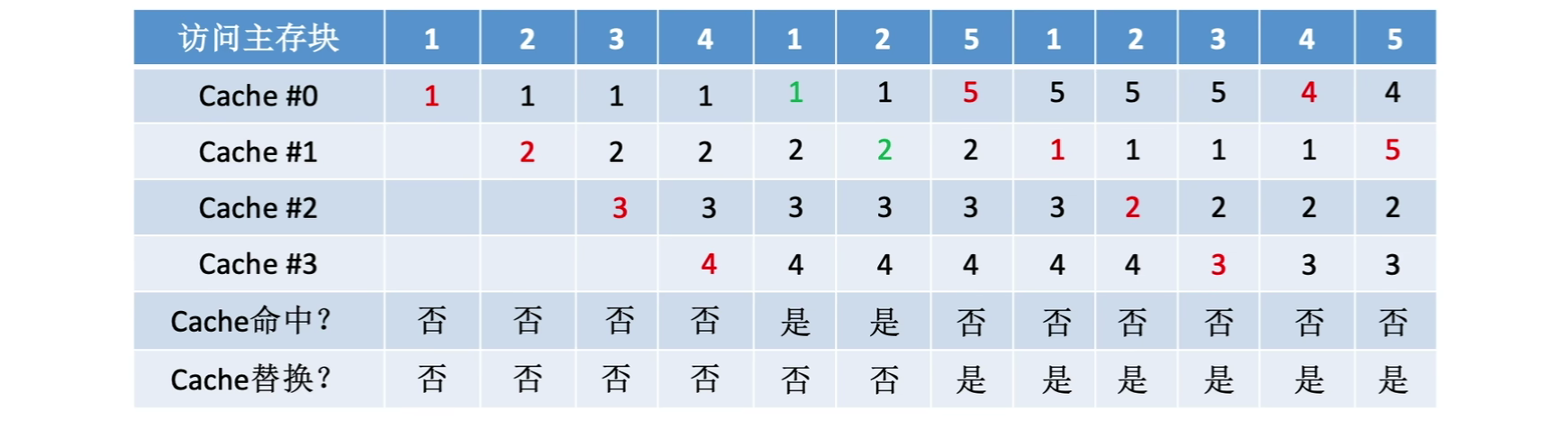
实现简单,但依然没有考虑局部性,最先被调入Cache的块也有可能是被频繁访问的
1.4.2.3近期最少使用算法(LRU,Least Recently Used)
为每一个Cache块设置一个"计数器",用于记录每个块已经多久没有被访问,当Cache满后替换"计数器"最大的
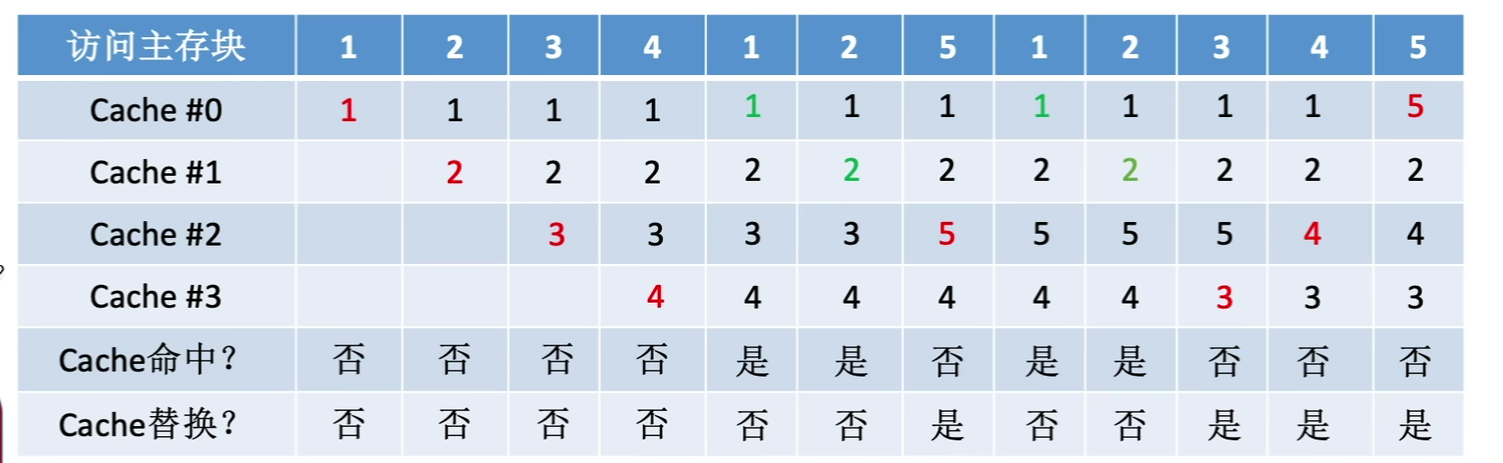
- 命中时,所命中的块的计数器要清零,其余不变
- 未命中且还有空闲块时候,新装入的块的计数器置零,其余非空闲块全加1
- 未命中且无空闲块时,计数值最大的块被淘汰,新装入的块的计数器置零,其余加1
1.4.2.4最不经常使用算法(LFU,Least Frequently Used)
为每一个Cache块设置一个"计数器",用于记录每个Cache块被访问了几次,当Cache满后替换"计数器"最小的
PS:若有多个最小的块,可按行号递增或FIFO策略进行替换
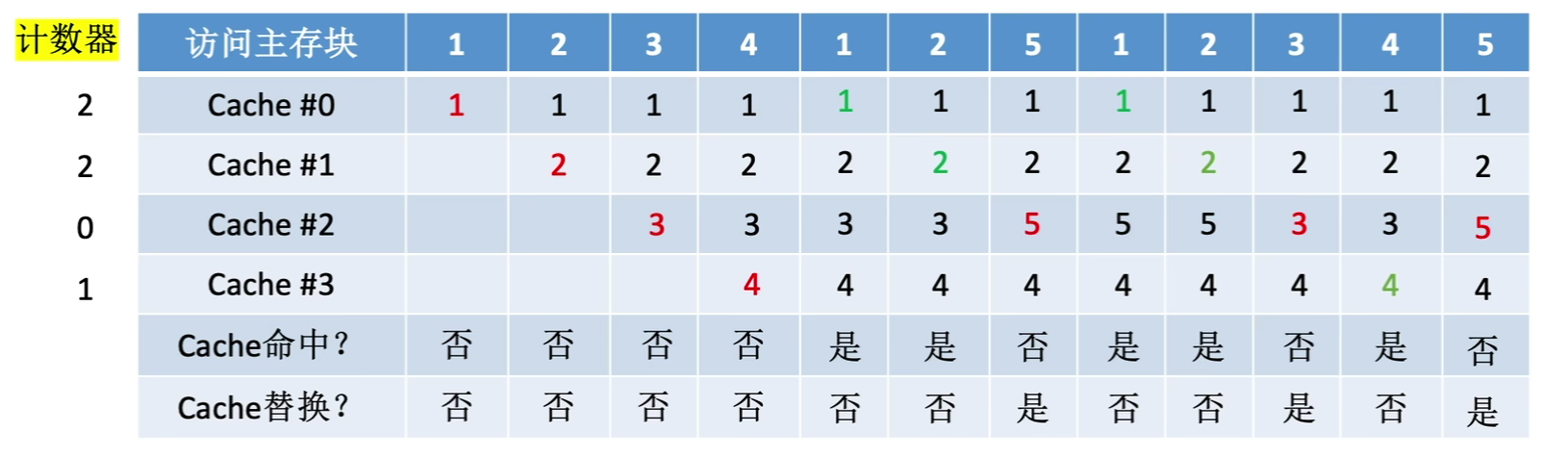
1.4.3 Cache写策略(数据一致性)
1.4.3.1写命中
(1)写回法
(2)全写法
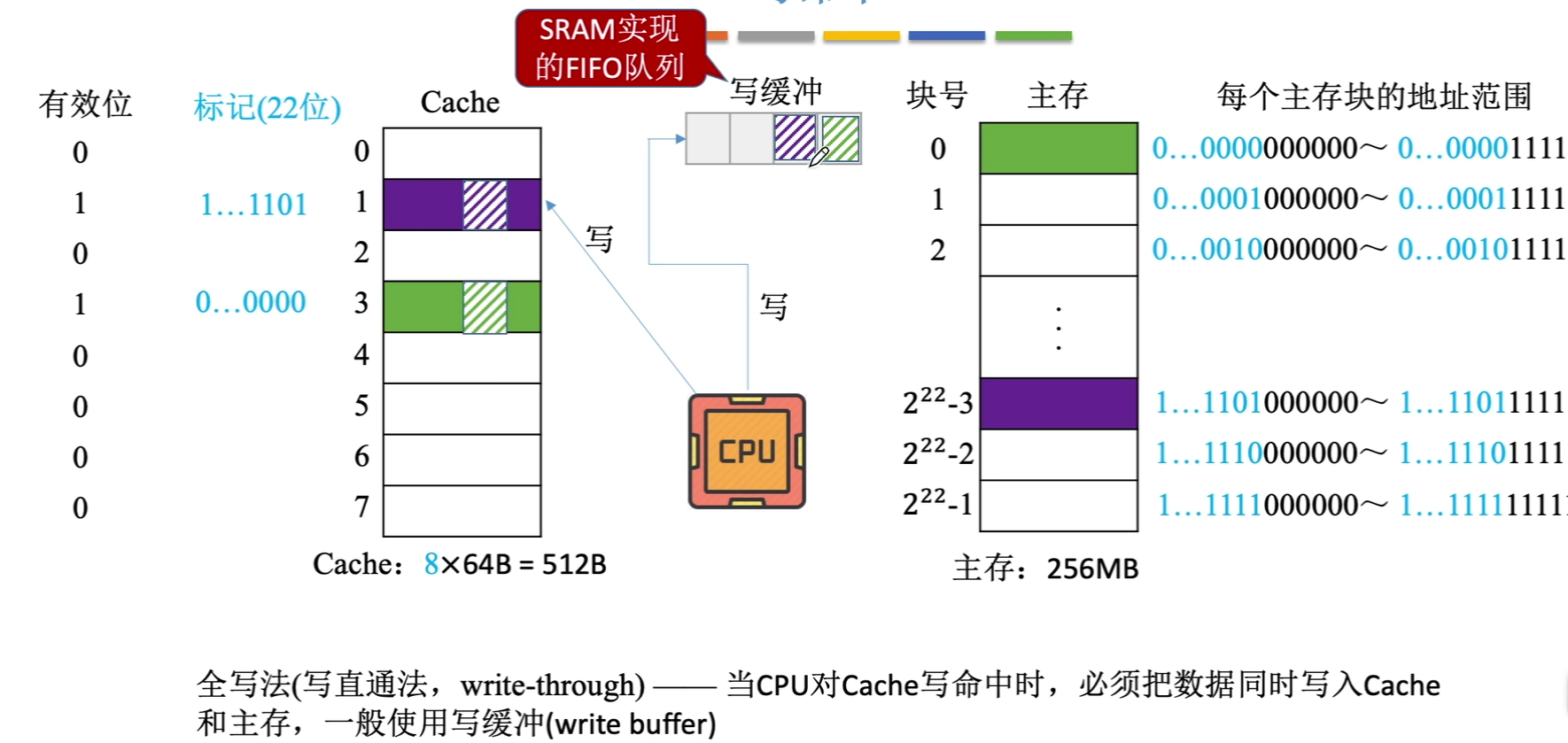
使用写缓冲,CPU的写速度很快,若写操作很频繁,可能回因为写缓冲饱和而发生阻塞,此时CPU就要等待。
1.4.3.2写不命中
(1)写分配法(write-allocate)
当CPU对Cache写不命中时,把主存的块调入Cache,再在Cache中修改,最后采用写回法
(2)非写分配法
当CPU对Cache写不命中时,只写入主存,不调入Cache,搭配全写法使用
1.5页式存储器
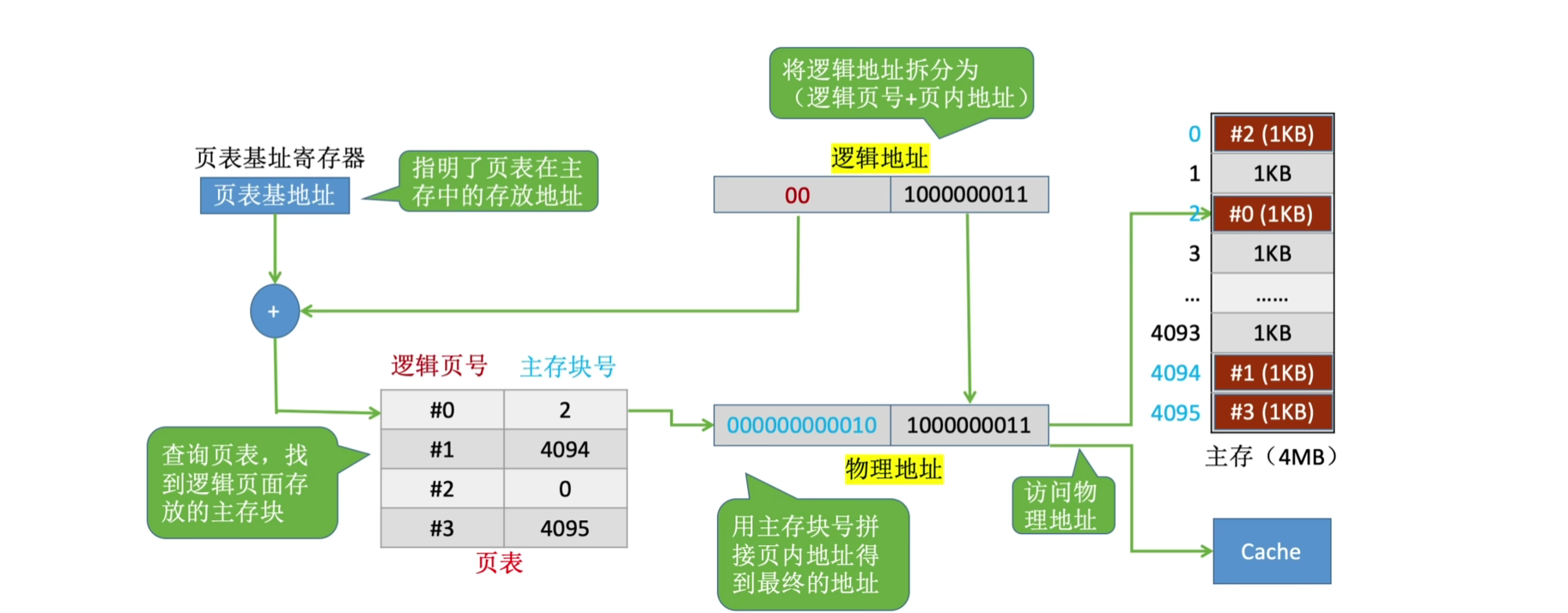
一个程序(进程)在逻辑上被分为若干个大小相等的"页面","页面"大小与"块"的大小相等,每个页面可以离散的放在不同的主存块中。
背景解析:如果不这样做,就需要在主存中寻找到连续的空间,导致主存利用率不高。
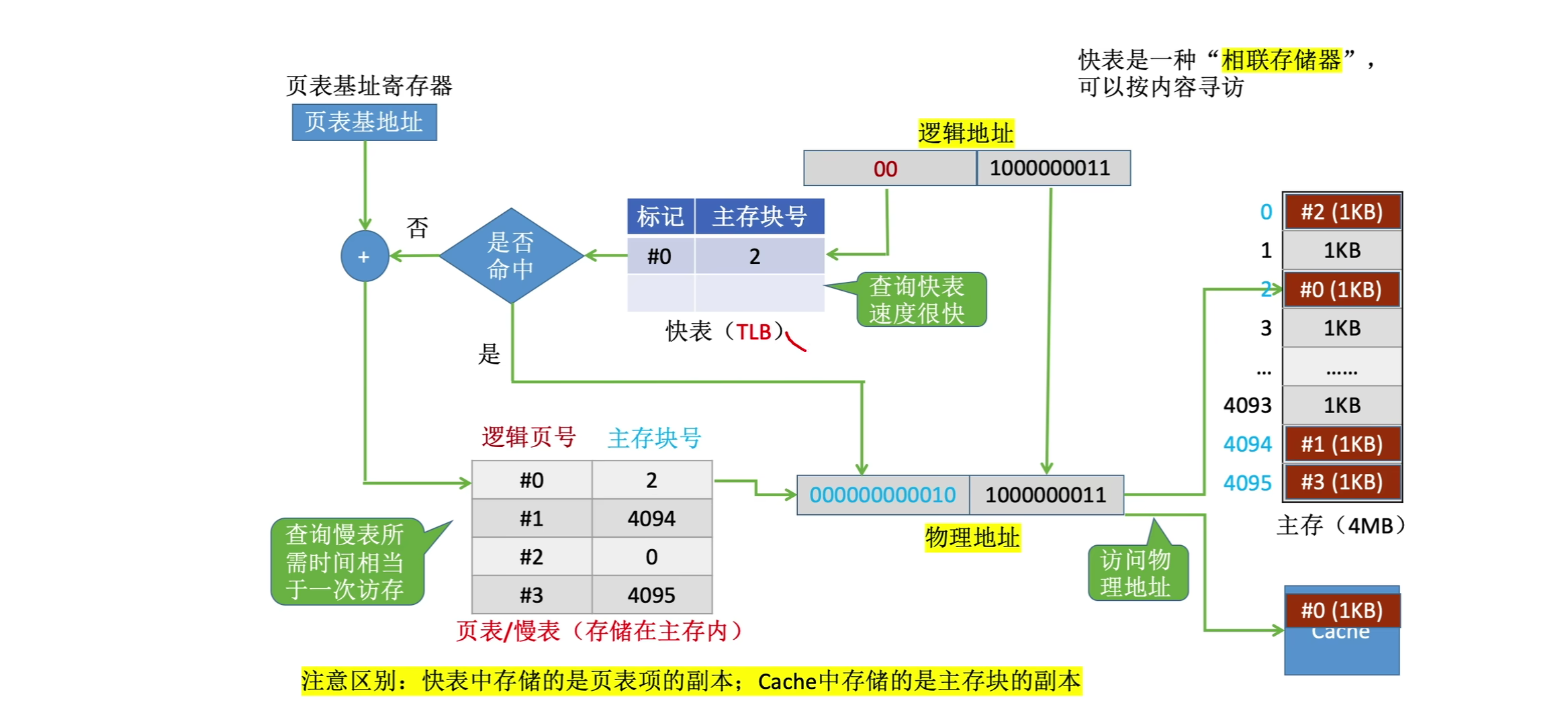
1.5.1地址变换方式
1.5.2引入快表(TLB)的变换