赛题:面向多模态大模型基础卷积算子优化
赛题代码:https://github.com/Vicczyq/PRA
一、赛题培训
采用HIP编程方法,在类GPU加速器DCU上进行并行计算
DCU加速卡使用的编程模型为AMD公司开发的ROCm模型,与CUDA编程类似
每个CU(对应SM)都有一块共享内存,大小为64KB,线程块共享
运行kernel:
1 | hipLaunchKernelGGL( kernel_phase2, //核函数名 |
hipprof工具的使用:
hipprof是DTK提供的性能分析工具,用于对HIP程序提供可视化性能分析
功能主要包括:单进程、多进程、多节点的HIP API跟踪、ROCTX跟踪,MPI日志解析等
1 | hipprof [options] <app conmand line> |
常用指令:
1 | hipprof --hip-trace ./test |
此为默认选项,不添加--hip-trace也会执行
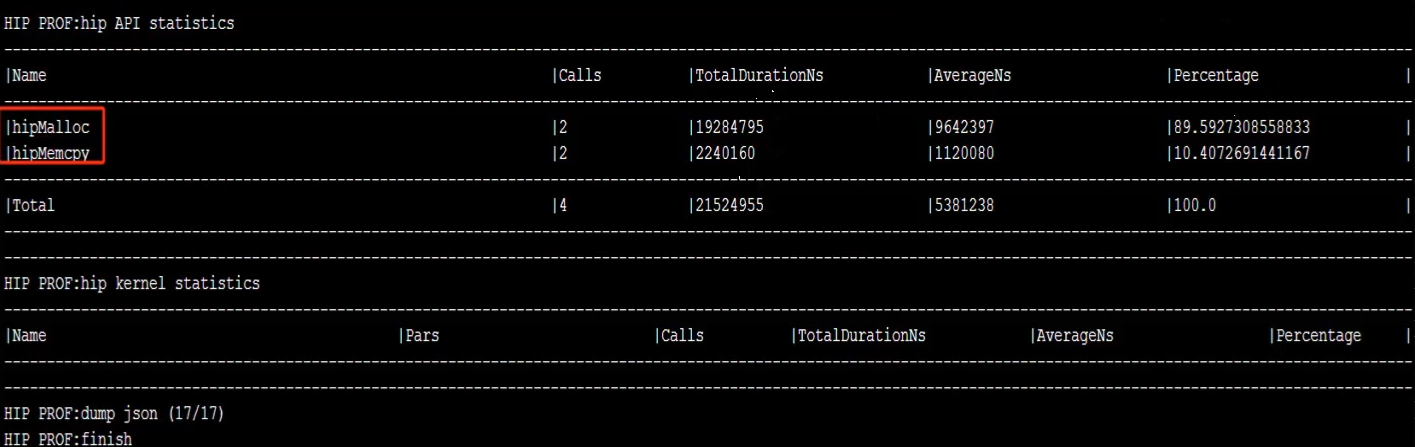
指令执行成功后会得到接口统计表和核函数统计表,并将其存储到两个csv文件中
同时为生成一个json文件进行辅助分析,
第一列为函数名、第二列为调用次数、第三列是函数总时间、第四列是平均每次时间、第五列是时间占用百分比,时间以ns为单位
可以用谷歌浏览器打开json文件,在浏览器中输入chrome://tracing,点击load载入即可

1.2 PMC指令
用于对硬件单元计数指标,如计算指令次数、时钟周期数、一级二级缓存读写次数等
1 | --pmc 开启常用的性能分析 |
1 | hipprof --pmc ./test |
1 | hipprof --pmc-read/--pmc-write ./test |
1.3 winograd算法
参考:https://blog.csdn.net/just_sort/article/details/108784138
1.3.1 原理
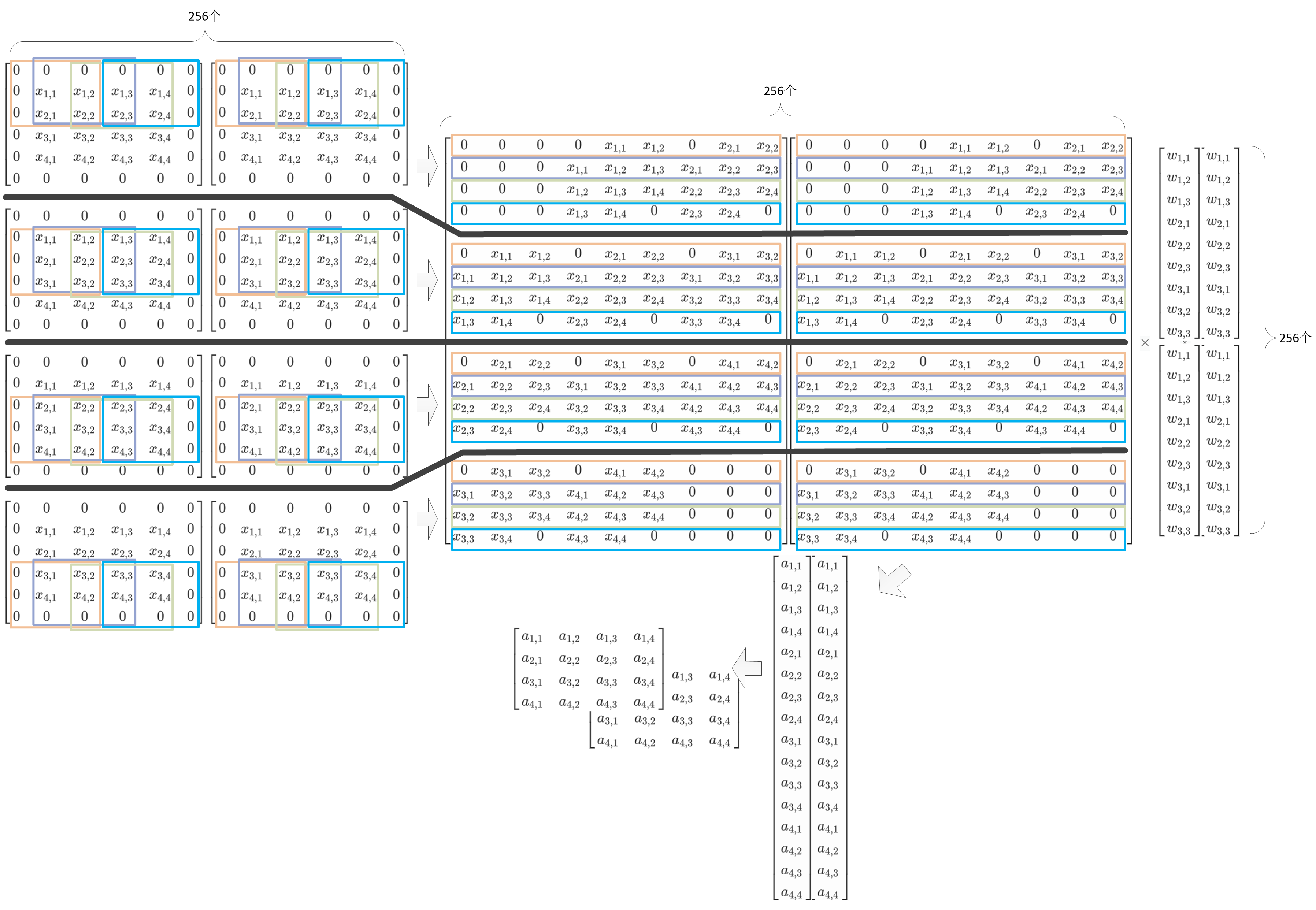
首先以一个以为卷积为例,输入为 \[ d = [d_0,d_1,d_2,d_3]^T \\ g = [g_0,g_1,g_2] \] 则卷积可以写为如下的矩阵乘形式
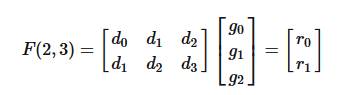
计算过程使用普通的矩阵乘法,则一共需要6次乘法和4次加法 。
由于中途存在大量的重复元素,winograd就利用这个特性
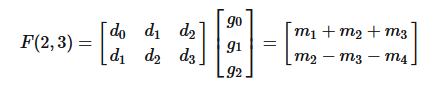
其中的
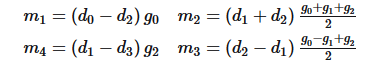
这样就可以达到加速的目的了。
1.3.2 计算
1.3.2.1 一维
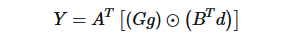
其中,⊙表示element-wise multiplication(Hadamard product)对应位置相乘
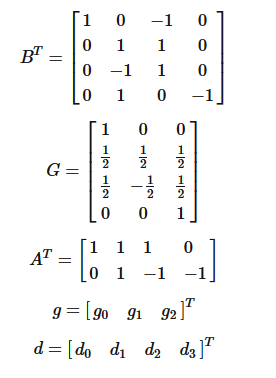
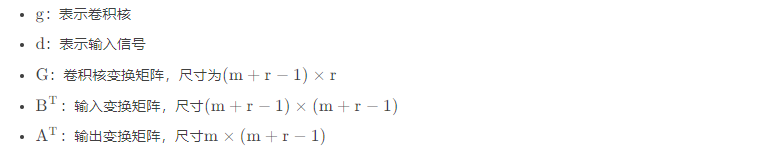
因此,整个过程可以分为:
- 输入变换
- 卷积核变换
- 外积
- 输出变换
1.3.2.2 二维
同理,只是公式复杂一点点
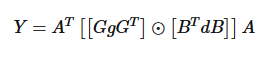
先进行输入矩阵、卷积核变换,再计算,再输出变换
G、\(G^T\)、B、\(B^T\)以及A这些矩阵是已知的,可以在github上面查找:https://github.com/andravin/wincnn
1.3.2.3 卷积计算
1 | _Float16* pin; //输入数据地址 |
https://www.bilibili.com/video/BV12G4y1B7nL
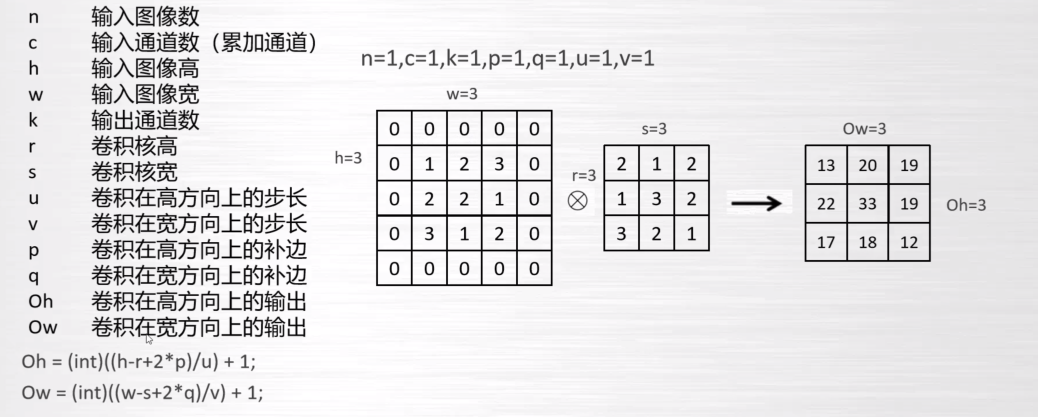
二、优化进行
1 | srun -p wzidnormal --gres=dcu:1 run.sh |
winograd:
im2col: