高性能程序 = 数据结构 + 算法 + 体系结构
优化效果 = 深入思考 + 敢于尝试 + 时间累积
学习资源
- intel Intrinsics Guide (opens new window)
- OpenMP 和 MPI :《并行程序设计导论》
- 现代微处理器架构 90分钟指南
- 高性能计算学习路线
- shell 脚本学习-bilibili
- 快速入门:Slurm资源管理与作业调度系统
- CMake和Makefile
一、基础知识
1.1 并行计算
并行计算是指在计算过程中同时执行多个任务或操作,以提高计算效率的技术。与传统的串行计算相比,它能够利用多个处理单元或计算资源同时进行计算,从而更快地完成任务。
1.1.1 分类:
- 指令级并行:CPU流水线
- 分布式并行:MPI
- 共享存储式并行:OpenMP、OpenACC、OpenCL
1.1.3 并行和并发的区别
并行:在同一时刻真正地并行处理多个任务,依赖于多处理器或多核心系统
并发:是指多个任务在同一时间段内交替执行,但不一定是同时执行的。
1.1.3 异构并行的概念
计算任务中使用具有不同架构的多种计算资源(例如CPU、GPU、神威主从核等)进行并行计算。

1.2 进程和线程
进程:资源分配的最小单位。是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。(资源分配)
线程:CPU调度的最小单位。是进程的一个执行单元,是进程内可调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。(执行体)
- 一个程序至少有一个进程,一个进程至少有一个线程
- 线程的划分尺度小于进程,使得多线程程序的并发性高
- 进程在执行过程中有独立的内存单元,而多线程之间是共享内存
OpenMP
- 并行粒度:线程级
- 数据分配方式:隐式(系统或编译器自动处理数据分配和管理)
- 共享存储,可扩展性差
MPI
- 并行粒度:进程级
- 数据分配方式:显式(由程序员自主分配)
- 分布式存储,可扩展性好
1.3 CPU内部架构
1.3.1 指令流水线(pipeline)
以经典的5级流水线为例,一条指令的执行被分为5个阶段:
- 取指(IF):从内存中取出一条指令
- 译码(ID):对指令进行解码,确定指令要执行的操作
- 执行(EX):执行指令操作
- 访存(MEM):内存访问操作
- 写回(WB):执行结果写回寄存器或内存

在CPU内部,执行每个阶段使用的是不同的硬件资源,从而可以让多条指令的执行时间相互重叠。
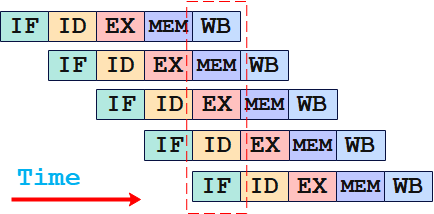
有了流水线技术,理想情况下,每个时钟周期,CPU可以完成一条指令的执行。那有没有什么方法,可以让CPU在每个时钟周期,完成多条指令的执行呢,这岂不是会大大提高CPU整体性能吗?这就是Superscalar技术!(还有VLIW技术)
1.3.2 超标量(Superscalar)
通过在CPU内部实现多条指令流水线,可以真正实现多条命令并行执行,也被称为多发射数据通路技术
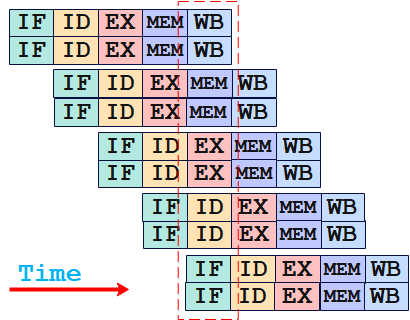
1.3.3 流水线冲突
在理想情况下,上述设计十分完美,但是现实中程序的指令序列之间往往存在各种各样的依赖和相关性,而CPU为了解决这种指令间的依赖和相关性,有时候不得不“停顿”下来,直到这些依赖得到解决,这就导致CPU指令流水线无法总是保持“全速运行”。
(1)数据冲突
两条在流水线中并行执行的指令,第二条指令需要用到第一条指令的执行结果,因此第二条指令的执行不得不暂停,一直到可以获取到第一条指令的执行结果为止。
1 | x = 某些计算; |
(2)控制冲突
CPU在执行分支跳转时,无法预知下一条要执行的指令。
1 | if(a > 100) { |
(3)结构冲突
多条指令同时竞争同一个硬件资源,由于硬件资源短缺,无法同时满足所有指令的执行请求。如两条并行执行的命令需要同时访问内存,而内存地址译码单元可能只有一个,这就产生了结构冲突。
1.4 高性能数学算法库
基本概念:计算领域的基础软件库,是发挥硬件算力的基石,提高效率
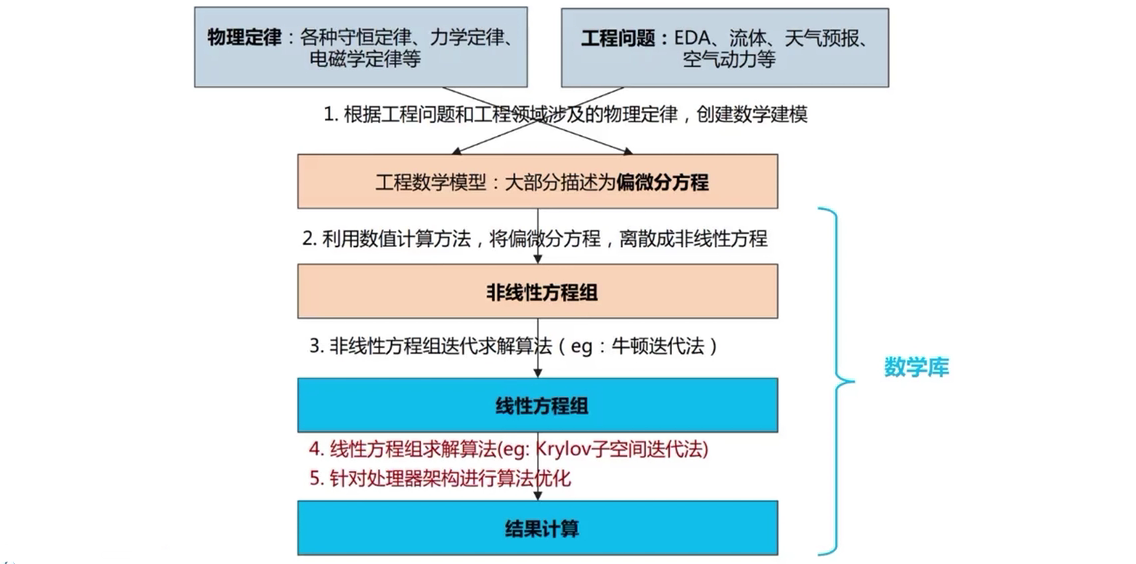
主流的硬件厂商都会为自身硬件提供优化了的算法库
- Intel MKL
- IBM ESSL/PESSL
- AMD AOCL
- Nvidia CUDA-X
1.4.1 BLAS/LAPACK
BLAS:基础线性代数子程序,是一系列初级操作的规范,如向量之间的乘法,矩阵乘法等
LAPACK:线性代数库,底层是BLAS,在此基础上定义了很多矩阵和高级运算函数,如矩阵分解、求逆等,运算效率比BLAS高
1.4.2 PETSc
底层为BLAS/LAPACK,用于高性能求解偏微积分方程组相关问题,目前PETSc所有消息传递均采用MPI实现。
支持Fortran 77/90、C/C++编写的串行和并行代码
1.5 计算机架构
划分计算机架构的方法有很多,广泛使用的为佛林分类法(Flynn’s Taxonomy)
1.5.1 佛林分类法(Flynn’s Taxonomy)
根据指令和数据进入CPU的方法进行分类
- 单指令单数据SISD(传统串行计算机,386)
- 单指令多数据SIMD(并行架构,比如向量机,所有核心指令唯一,但是数据不同,现在CPU基本都有这类的向量指令)
- 多指令单数据MISD(少见,多个指令围殴一个数据)
- 多指令多数据MIMD(并行架构,多核心,多指令,异步处理多个数据流,从而实现空间上的并行,MIMD多数情况下包含SIMD,就是MIMD有很多计算核,计算核支持SIMD)
1.5.2 根据内存划分
1.5.2.1 分布式内存的多节点系统
通常把这种成为集群,节点有独立的硬件,节点与节点之间通过网络进行交互(MPI的作用)
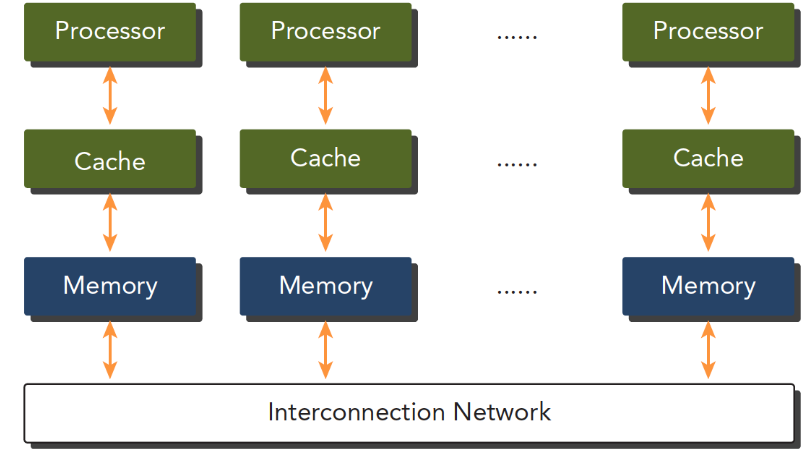
1.5.2.2 共享内存的多处理器系统
单个主板上面有多个处理器,他们共享主板上面的内存,通过PCIe和内存进行交互
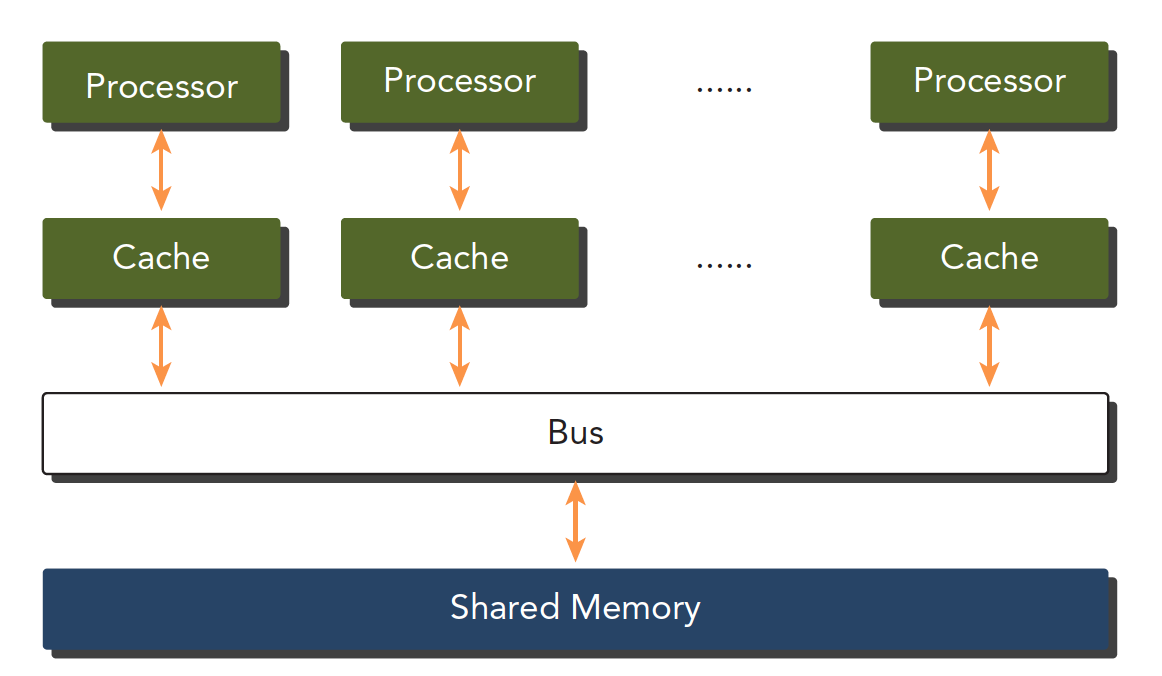
上面讲到的”多个处理器“可以分为 多片处理器 和 单片多核(众核),也就是说有些主板上安装了许多片处理器,也有的是一个主板上就一个处理器,但是这个处理器里面有几百个核。
GPU就属于众核系统。当然现在CPU也都是多核的了,但是他们还是有很大区别的:
- CPU适合执行复杂的逻辑,比如多分支,其核心比较重(复杂)
- GPU适合执行简单的逻辑,大量的数据计算,其吞吐量更高,但是核心比较轻(结构简单)
二、入门篇
PS:在这之前最好学好C++的相关知识
2.1 Pthread
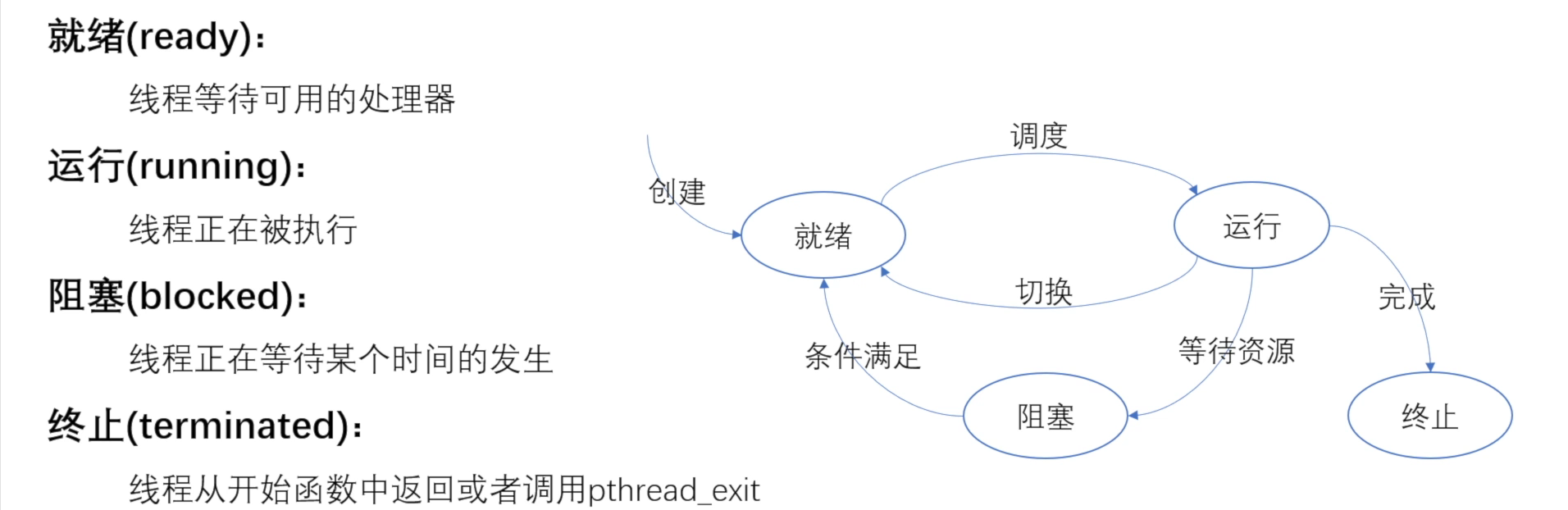
pthread是许多并行模型的底层实现
具体内容:https://vicczyq.github.io/2024/05/21/Pthread
2.2 OpenMP
以Pthread为基础开发的,面向多线程并行编程模型,极大简化了多线程编码,支持Fortran、C/C++
详细内容:https://vicczyq.github.io/2022/02/05/OpenMP学习
三、基础篇
3.1 MPI
详细内容:https://vicczyq.github.io/2022/02/05/MPI%E5%AD%A6%E4%B9%A0/
3.2 CUDA
详细内容:
https://vicczyq.github.io/2022/02/09/CUDA/
上面这篇更完善一点,下面这个比较浅,凑合速成懒得删了
https://vicczyq.github.io/2022/02/05/CUDA%E5%9F%BA%E7%A1%80%E5%AD%A6%E4%B9%A0/
3.3 性能分析
3.3.1 静态分析工具
利用代码静态分析,对代码进行数据对象、函数接口封装和调用分析
主流的工具:Understand、SourceInsight、DeepScan、deepsource、VERACODE
以Understand为例:https://blog.csdn.net/qq_40513792/article/details/111991978
3.3.2 动态分析工具
实际运行过程中调用了哪些函数。
主流的工具:gprof、intel vtune profiler、Perf等
Perf
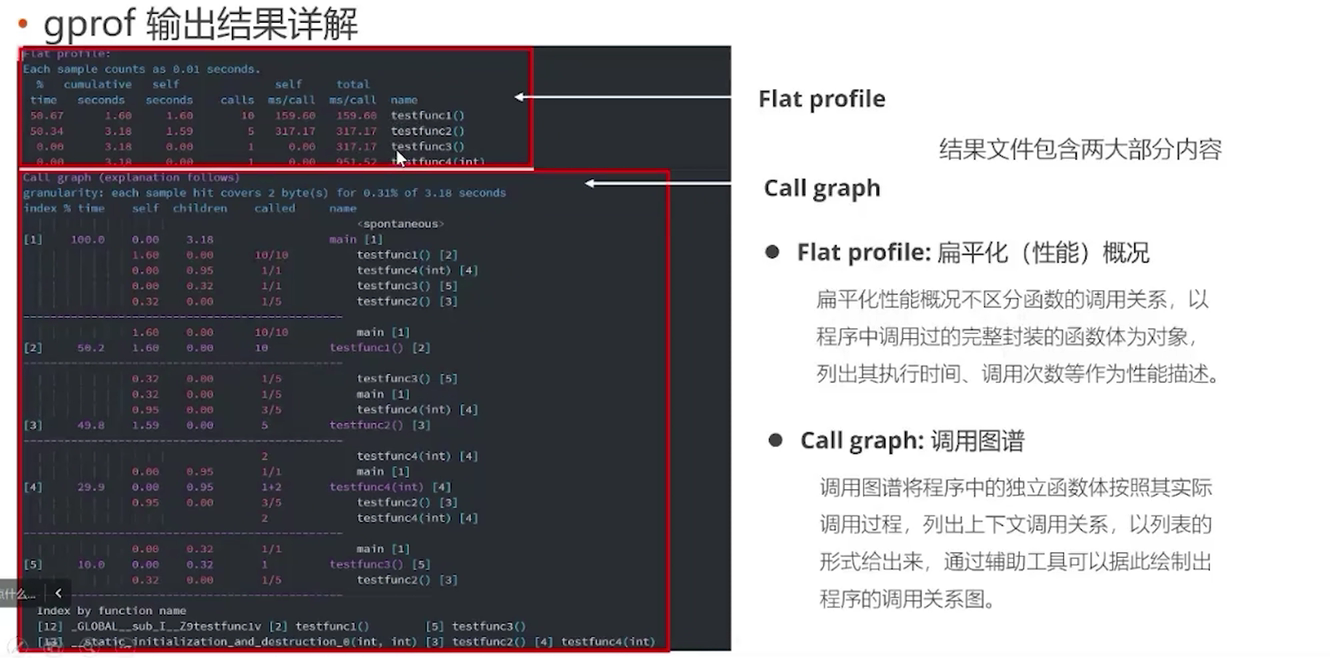
gprof(GNU profile)
注意:不适用于多线程程序,只会记录主线程。
用gcc、g++等编译程序时,使用-pg参数,编译器会在原代码中插入用于性能测试的代码片断
如:g++ -pg -o test test.cpp
执行编译后的可执行程序,如:./test
程序运行结束后,会在程序所在路径下生成一个缺省文件名为gmon.out的文件
最后使用gprof test gmon.out > output.txt即可
intel vtune profiler
针对于英特尔处理器。
3.4 SIMD
AVX:Advanced Vector Extension 高级向量扩展
AVX是SIMD(单指令多数据)指令,可以用一条指令产生多个并行操作。
寄存器位宽:
- SSE:128bit
- AVX/AVX2:256bit
- AVX512:512bit
因为AVX/AVX2都支持256bit,所以可以统称为AVX256
更多内容见:https://blog.csdn.net/qq_17075011/article/details/130555559
四、其他常用优化手段
4.1 常用循环优化技术
(1)输入值嵌入
将运行时需要从文件读入的关键数据转换为编译时的静态可知数据
例子如下:
1 |
|
如果我已经知道需要读入的数据value的值为0,就可以直接采用宏定义或者静态变量的方法,不需要去读入
1 |
(2)分支消除
消除循环中的分支,减少分支判断和跳转
也可以用补码/位运算
例如:
1 | for(int i = 0; i < 100; i++){ |
修改为:
1 | for(int i = 0; i < 30; i++){ |
(3)循环合并
每次循环需要对循环条件进行判断(i<N?)循环合并可以减少判断次数。
如果A,B操作数据有关联,甚至可以减少IO
1 | for(int i = 0; i < N; i++){ |
修改为
1 | for(int i = 0; i < N; i++){ |
(4)次序交换
C/C++存储是按行优先存储,Fortran是列优先存储
在对数据进行访问时,最好按照顺序进行访问。
原理是最大化利用高速缓存Cache
1 | for(int i = 0; i < N; i++){ |
(5)循环分块
目的是提高Cache的命中率,
一个Cache line被使用过之后,后面可能还会使用,但是默认循环的方式,到下次要使用的时候Cache line已经被替换。
于是我们就把循环重新排一下,使得一个Cache line在被替换之前就能被再次使用
例:
1 | for(i = 0; i < N; i++){ |
如果当前Cache Line的大小为 b ,A的cache
miss次数就为N/b,B的cache miss次数为N*M/b

因此就可以划分块,令块大小为T(一般是b的整数倍,也要足够小)
1 | for(jj = 0; jj < M; jj += T){ |
(6)循环展开
循环条件判断次数减少,更大的代码块有更多优化手段
现在有一个代码
1 | int calc(int n){ |
对代码进行循环展开,假设n是4的倍数(如果不是4的倍数要边界处理)
1 | //test_1 |
1 | //test_2 |
test_2和test_1都属于循环展开,但是test_1效果更好
内容前提补充:流水线,见 1.3
test_1是这样展开的
1 | fact0 *= i; |
test_2是这样展开的
1 | fact *= i; |
很明显,test_2的后一条指令执行前,必须知道前一条指令的计算结果,这也就是数据依赖,造成流水线冲突。
虽然通过循环展开,减少了无用指令,也减少了热点路径上分支跳转引起的流水线控制冲突,但它同时引入了数据依赖,进而导致流水线冲突,仍然无法发挥流水线和superscalar的指令级并行执行的能力!
补充:优化热点路径内存访问
定义局部变量时加上register关键字即可,
作用是建议编译器尽可能把变量放在寄存器中,以求更快的访问速度
1 | int calc(int n){ |
4.2 cache优化
4.2.1 指令cache优化
将需要多次调用的函数设置为内联函数inline,减少函数调用开销
inline
关键字可以建议编译器在调用该函数的地方直接插入函数代码,而不是执行正常的函数调用。
1 | inline int add(int a, int b) { |
4.2.2 数据cache优化
数据预取:在本次计算中,预取下一次需要的数据。
1 | //使用GCC内置函数实现 |
数据重排:把数据重新排列(行优先或列优先),使其对Cache访问更为友好,减少Cache miss
4.3 逻辑优化
选择合适编译级别(O0123)
使用register关键字,将常访问变量放入寄存器
使用快速数学计算(-ffast-math)等